我是什么fw😢
[toc]
入门
进制
十进制和二进制
介绍:对于一个十进制数A,将A转换为二进制数,然后按位逆序排列,再转换为十进制数B,我们称B为A的二进制逆序数。
例如对于十进制数173,它的二进制形式为10101101,逆序排列得到10110101,其十进制数为181,181即为173的二进制逆序数。
重点就是大数的十进制和二进制互转。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 #include <bits/stdc++.h> using namespace std;string d2b (char s[1000 ]) { string result; int num[1000 ]; int len = strlen (s); for (int i = 0 ; i < 1000 ; i++){ num[i] = s[i] - '0' ; } int i = 0 ; while (i < len){ int c = 0 ; result += num[len-1 ] % 2 + '0' ; for (int j = 0 ; j < len; j++){ int tmp = num[j]; num[j] = (num[j] + c) / 2 ; if (tmp % 2 == 1 ) c = 10 ; else c = 0 ; } if (num[i] == 0 ) i++; } reverse (result.begin (), result.end ()); return result; } string b2d (string sb) { int len = sb.size (); int upb = 1 ; int res_d[1000 ] = {0 }; string result; for (int i = 0 ; i < len; i++){ for (int j = 0 ; j < upb; j++){ if (j == 0 ){ res_d[j] = res_d[j] * 2 + (sb[i] - '0' ); } else { res_d[j] = res_d[j] * 2 ; } } for (int k = 0 ; k < upb; k++){ if (res_d[k] > 9 ){ res_d[k+1 ]++; res_d[k] %= 10 ; if (k == upb - 1 ){ upb ++ ; } } } } for (int i = upb - 1 ; i >= 0 ; i--){ result += res_d[i] + '0' ; } return result; } int main () char s[1000 ]; while (cin >> s){ string sb = d2b (s); reverse (sb.begin (), sb.end ()); string res = b2d (sb); cout << res << endl; } return 0 ; }
进制转换M2N
就是在M进制转十进制的时候把进位的10改成n(十进制转N进制其实没必要单独写了)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <bits/stdc++.h> using namespace std;string m2n (int m, int n, string num) { int len = num.size (); int upb = 1 ; int res_d[1000 ] = {0 }; string result; for (int i = 0 ; i < len; i++){ for (int j = 0 ; j < upb; j++){ if (j == 0 ){ if ((num[i] - '0' ) < 10 ) res_d[j] = res_d[j] * m + (num[i] - '0' ); else res_d[j] = res_d[j] * m + (num[i] - 'A' + 10 ); } else { res_d[j] = res_d[j] * m; } } for (int k = 0 ; k < upb; k++){ if (res_d[k] > n-1 ){ res_d[k+1 ] += res_d[k] / n; res_d[k] %= n; if (k == upb - 1 ){ upb ++ ; } } } } for (int i = upb - 1 ; i >= 0 ; i--){ if (n > 9 ){ if (res_d[i] > 9 ){ result += (res_d[i] - 10 + 'a' ); } else { result += res_d[i] + '0' ; } } else { result += res_d[i] + '0' ; } } return result; } int main () int m, n; while (cin >> m >> n){ string m_num; cin >> m_num; string n_num = m2n (m, n, m_num); cout << n_num << endl; } return 0 ; }
负二进制
注意C里面除以-2的余数有好几种情况,-1-0-1都有可能;
还有边界输入0考虑一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <bits/stdc++.h> using namespace std;int main () int ip; while (cin >> ip){ string op; if (ip == 0 ){ cout << 0 << endl; continue ; } while (ip!=0 ){ int r = ip % -2 , k = ip / -2 ; if (r == 0 ){ ip = k; op += r + '0' ; } else if (r == -1 ){ ip = k+1 ; op += r+2 +'0' ; } else if (r == 1 ){ ip = k; op += r + '0' ; } } reverse (op.begin (), op.end ()); cout << op << endl; } }
排序
旋转矩阵
函数调用二维数组和返回指针有点折磨,最后还是定义了全局变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 #include <bits/stdc++.h> using namespace std;int data[100 ][100 ];int s[100 ][100 ];void one (int n, int m) for (int i = 0 ; i < m; i++){ for (int j = 0 ; j < n; j++){ data[i][j] = s[n-j-1 ][i]; } } for (int i = 0 ; i < m; i++){ for (int j = 0 ; j < n; j++){ s[i][j] = data[i][j]; } } } void two (int n, int m) for (int i = 0 ; i < m; i++){ for (int j = 0 ; j < n; j++){ data[i][j] = s[j][m-1 -i]; } } for (int i = 0 ; i < m; i++){ for (int j = 0 ; j < n; j++){ s[i][j] = data[i][j]; } } } void three (int n, int m) for (int i = 0 ; i < n; i++){ for (int j = 0 ; j < m; j++){ data[i][j] = s[i][m-j-1 ]; } } for (int i = 0 ; i < n; i++){ for (int j = 0 ; j < m; j++){ s[i][j] = data[i][j]; } } } int main () int n, m, k; while (cin >> n >> m >> k){ for (int i = 0 ; i < n; i++){ for (int j = 0 ; j < m; j++){ cin >> s[i][j]; } } for (int i = 0 ; i < k; i++){ int k_; cin >> k_; if (k_ == 1 ){ one (n, m); int tmp = m; m = n; n = tmp; } else if (k_ == 2 ){ two (n, m); int tmp = m; m = n; n = tmp; } else if (k_ == 3 ){ three (n, m); } } for (int i = 0 ; i < n; i++){ for (int j = 0 ; j < m; j++){ cout << s[i][j] << " " ; } cout << endl; } } return 0 ; }
2048
我是每次反着遍历,然后把找不为0的值,如果下一个不相等就存在一个数组里,如果找到相等的就*2再存。每次找到不等于0的值一定要存,在这里卡了很久。
看别人的答案是比较规矩的:先移到一侧,再合并,再移到一侧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 #include <bits/stdc++.h> using namespace std;int data[4 ][4 ];int s[4 ][4 ];int main () int n; while (cin >> n){ for (int i = 0 ; i < 4 ; i++){ for (int j = 0 ; j < 4 ; j++){ cin >> s[i][j]; } } if (n == 1 ){ for (int i = 0 ; i < 4 ; i++){ int tmp[4 ] = {0 }, idx = 0 ; for (int j = 0 ; j < 4 ; j++){ if (s[j][i] != 0 ){ if (j != 3 ){ int jud = 1 ; for (int k = j+1 ; k < 4 ; k++){ if (s[k][i] == 0 ) continue ; if (s[k][i] == s[j][i]){ tmp[idx++] = 2 * s[j][i]; j = k; jud = 0 ; break ; } else { tmp[idx++] = s[j][i]; jud = 0 ; break ; } } if (jud){ tmp[idx++] = s[j][i]; } } else { tmp[idx++] = s[j][i]; } } } for (int j = 0 ; j < 4 ; j++){ s[j][i] = tmp[j]; } } } else if (n == 2 ){ for (int i = 0 ; i < 4 ; i++){ int tmp[4 ] = {0 }, idx = 0 ; for (int j = 3 ; j >= 0 ; j--){ if (s[j][i] != 0 ){ if (j != 0 ){ int jud = 1 ; for (int k = j - 1 ; k >= 0 ; k--){ if (s[k][i] == 0 ) continue ; if (s[k][i] == s[j][i]){ tmp[idx++] = 2 * s[j][i]; j = k; jud = 0 ; break ; } else { tmp[idx++] = s[j][i]; jud = 0 ; break ; } } if (jud){ tmp[idx++] = s[j][i]; } } else { tmp[idx++] = s[j][i]; } } } for (int j = 3 ; j >= 0 ; j--){ s[j][i] = tmp[3 -j]; } } } else if (n == 3 ){ for (int i = 0 ; i < 4 ; i++){ int tmp[4 ] = {0 }, idx = 0 ; for (int j = 0 ; j < 4 ; j++){ if (s[i][j] != 0 ){ if (j!=3 ){ int jud = 1 ; for (int k = j + 1 ; k < 4 ; k++){ if (s[i][k] == 0 ) continue ; if (s[i][j] == s[i][k]){ tmp[idx++] = 2 * s[i][j]; j = k; jud = 0 ; break ; } else { tmp[idx++] = s[i][j]; jud = 0 ; break ; } } if (jud){ tmp[idx++] = s[i][j]; } } else { tmp[idx++] = s[i][j]; } } } for (int j = 0 ; j < 4 ; j++){ s[i][j] = tmp[j]; } } } else if (n == 4 ){ for (int i = 0 ; i < 4 ; i++){ int tmp[4 ] = {0 }, idx = 0 ; for (int j = 3 ; j >= 0 ; j--){ if (s[i][j] != 0 ){ if (j != 0 ){ int jud = 1 ; for (int k = j - 1 ; k >= 0 ; k--){ if (s[i][k] == 0 ) continue ; if (s[i][j] == s[i][k]){ tmp[idx++] = 2 * s[i][j]; j = k; jud = 0 ; break ; } else { tmp[idx++] = s[i][j]; jud = 0 ; break ; } } if (jud){ tmp[idx++] = s[i][j]; } } else { tmp[idx++] = s[i][j]; } } } for (int j = 3 ; j >= 0 ; j--){ s[i][j] = tmp[3 -j]; } } } for (int i = 0 ; i < 4 ; i++){ for (int j = 0 ; j < 4 ; j++){ cout << s[i][j] << " " ; } cout << endl; } } return 0 ; }
日期
日期差值
同一年用一个函数来写;
不同年的拆成三部分,第一年数据到年底、中间、第二年年初到数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 #include <bits/stdc++.h> using namespace std;struct data { int year, month, day; }; bool is_lunar (int y) if (y%400 ==0 || (y%4 ==0 && y%100 !=0 )) return true ; else return false ; } int cal_days (struct data d1, struct data d2) int f[13 ] = {0 , 31 , 28 , 31 , 30 , 31 , 30 , 31 , 31 , 30 , 31 , 30 , 31 }; int ans = 0 ; if (d1.month == d2.month) ans = d2.day - d1.day + 1 ; else { if (is_lunar (d1.year)){ f[2 ] = 29 ; } else { f[2 ] = 28 ; } f[d1.month] -= d1.day; ans = d2.day + 1 ; for (int i = d1.month; i < d2.month; i++){ ans += f[i]; } } return ans; } int main () char r1[10 ], r2[10 ]; while (cin >> r1 >> r2){ struct data d1, d2; d1.year = (r1[0 ]-'0' ) * 1000 + (r1[1 ]-'0' ) * 100 + (r1[2 ]-'0' ) * 10 + (r1[3 ]-'0' ); d1.month = (r1[4 ]-'0' ) * 10 + (r1[5 ]-'0' ); d1.day = (r1[6 ]-'0' ) * 10 + (r1[7 ]-'0' ); d2.year = (r2[0 ]-'0' ) * 1000 + (r2[1 ]-'0' ) * 100 + (r2[2 ]-'0' ) * 10 + (r2[3 ]-'0' ); d2.month = (r2[4 ]-'0' ) * 10 + (r2[5 ]-'0' ); d2.day = (r2[6 ]-'0' ) * 10 + (r2[7 ]-'0' ); int ans = 0 ; if (d1.year == d2.year){ ans = cal_days (d1, d2); } else { struct data d3 = { d1.year, 12 , 31 }; ans += cal_days (d1, d3); for (int i = d1.year+1 ; i < d2.year; i++){ if (is_lunar (i)) ans += 366 ; else ans += 365 ; } struct data d4 = { d2.year, 1 , 1 }; ans += cal_days (d4, d2); } cout << ans << endl; } return 0 ; }
打印日期
格式化输出啥的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <bits/stdc++.h> using namespace std;bool is_lunar (int y) if (y%400 ==0 || (y%4 ==0 && y%100 !=0 )) return true ; else return false ; } int main () int y, d; while (cin >> y >> d){ int f[13 ] = {0 , 31 , 28 , 31 , 30 , 31 , 30 , 31 , 31 , 30 , 31 , 30 , 31 }; if (is_lunar (y)) f[2 ] = 29 ; else f[2 ] = 28 ; int ans = 1 , i = 1 ; while (d > f[i]){ d -= f[i]; i++; } printf ("%d-%02d-%02d\n" , y, i, d); } return 0 ; }
日期累加
设计一个程序能计算一个日期加上若干天后是什么日期。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <bits/stdc++.h> using namespace std;bool is_lunar (int y) if (y%400 ==0 || (y%4 ==0 && y%100 !=0 )) return true ; else return false ; } int main () int m; cin >> m; for (int i = 0 ; i < m; i++){ int y, m, d, n; cin >> y >> m >> d >> n; d += n; int f[13 ] = {0 , 31 , 28 , 31 , 30 , 31 , 30 , 31 , 31 , 30 , 31 , 30 , 31 }; if (is_lunar (y)) f[2 ] = 29 ; else f[2 ] = 28 ; int y_ = y; while (d > f[m]){ d -= f[m]; m ++; if (m > 12 ){ m -= 12 ; y ++; } if (y_ != y){ y_ = y; if (is_lunar (y)) f[2 ] = 29 ; else f[2 ] = 28 ; } } printf ("%d-%02d-%02d\n" , y, m, d); } return 0 ; }
排序
sort和stable_sort
成绩排序
题目:输入任意(用户,成绩)序列,可以获得成绩从高到低或从低到高的排列,相同成绩都按先录入排列在前的规则处理。
两种办法:
用stable_sort
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <bits/stdc++.h> using namespace std;struct student { string name; int grade; }; bool desc (struct student s1, struct student s2) return s1.grade > s2.grade; } bool asc (struct student s1, struct student s2) return s1.grade < s2.grade; } int main () int n, order; while (cin >> n >> order){ struct student stu[100 ]; for (int i = 0 ; i < n; i++){ cin >> stu[i].name >> stu[i].grade; } if (order == 0 ){ stable_sort (stu, stu+n, desc); } else { stable_sort (stu, stu+n, asc); } for (int i = 0 ; i < n; i++){ cout << stu[i].name << " " << stu[i].grade << endl; } } return 0 ; }
二级排序
设置一个id,成绩相同id小的在上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <bits/stdc++.h> using namespace std;struct student { string name; int grade, id; }; bool desc (struct student s1, struct student s2) if (s1.grade == s2.grade) return s1.id < s2.id; return s1.grade > s2.grade; } bool asc (struct student s1, struct student s2) if (s1.grade == s2.grade) return s1.id < s2.id; return s1.grade < s2.grade; } int main () int n, order; while (cin >> n >> order){ struct student stu[1000 ]; for (int i = 0 ; i < n; i++){ cin >> stu[i].name >> stu[i].grade; stu[i].id = i; } if (order == 0 ){ sort (stu, stu+n, desc); } else { sort (stu, stu+n, asc); } for (int i = 0 ; i < n; i++){ cout << stu[i].name << " " << stu[i].grade << endl; } } return 0 ; }
排序
输入n个数进行排序,要求先按奇偶后按从小到大的顺序排序。
也有两种办法,一个是奇偶分开排,一个是二级排序,把奇数排在偶数前面;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <bits/stdc++.h> using namespace std;int main () int n; while (cin >> n){ int m[1000 ]={0 }, odd[1000 ]={0 }, even[1000 ]={0 }; for (int i = 0 ; i < n; i++){ cin >> m[i]; } int idx1 = 0 , idx2 = 0 ; for (int i = 0 ; i < n; i++){ if (m[i] % 2 == 0 ) even[idx1++] = m[i]; else odd[idx2++] = m[i]; } sort (odd, odd+idx2); sort (even, even+idx1); for (int i = 0 ; i < idx2; i++){ cout << odd[i] << " " ; } for (int i = 0 ; i < idx1; i++){ cout << even[i] << " " ; } cout << endl; } }
分级:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <bits/stdc++.h> using namespace std;bool compare (int a, int b) if (a % 2 == b % 2 ) return a < b; else return (a%2 ) > (b%2 ); } int main () int n; while (cin >> n){ int m[1000 ]={0 }; for (int i = 0 ; i < n; i++){ cin >> m[i]; } sort (m, m+n, compare); for (int i = 0 ; i < n; i++){ cout << m[i] << " " ; } cout << endl; } }
排序2
编写程序实现直接插入排序、希尔排序(d=5)、直接选择排序、快速排序和二路归并排序算法。
直接插入排序后的结果 一趟希尔排序后的结果 直接选择排序后的结果
快速排序后的结果 一趟二路归并排序后的结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 #include <bits/stdc++.h> using namespace std;void insert_sort (int arr[], int len) for (int i = 1 ; i < len; i++){ int tmp = arr[i]; int j = i - 1 ; while ((j >= 0 ) && (arr[j] > tmp)){ arr[j+1 ] = arr[j]; j--; } arr[j+1 ] = tmp; } for (int i = 0 ; i < len; i++){ cout << arr[i] << " " ; } cout << endl; } void shell_sort_onetime (int arr[], int len) int gap = 5 ; for (int i = gap; i < len; i++){ int tmp = arr[i], j; for (j = i - gap; j >=0 && arr[j] > tmp; j -= gap){ arr[j + gap] = arr[j]; } arr[j + gap] = tmp; } for (int i = 0 ; i < len; i++){ cout << arr[i] << " " ; } cout << endl; } void select_sort (int arr[], int len) int idx; for (int i = 0 ; i < len; i++){ idx = i; for (int j = i + 1 ; j < len; j++){ if (arr[j] < arr[idx]) idx = j; } int tmp = arr[i]; arr[i] = arr[idx]; arr[idx] = tmp; } for (int i = 0 ; i < len; i++){ cout << arr[i] << " " ; } cout << endl; } void quick_sort (int arr[], int l, int r) if (l >= r) return ; int i = l, j = r, x = arr[l]; while (i < j){ while (arr[j] >= x && i < j) j--; if (i < j) arr[i++] = arr[j]; while (arr[i] <= x && i < j) i++; if (i < j) arr[j--] = arr[i]; } arr[i] = x; quick_sort (arr, l, i - 1 ); quick_sort (arr, j + 1 , r); } void start_quick_sort (int arr[], int len) quick_sort (arr, 0 , len-1 ); for (int i = 0 ; i < len; i++){ cout << arr[i] << " " ; } cout << endl; } void twomerge_onetime (int arr[], int len) for (int i = 0 ; i < len-1 ; i += 2 ){ if (arr[i] > arr[i+1 ]) swap (arr[i], arr[i+1 ]); } for (int i = 0 ; i < len; i++){ cout << arr[i] << " " ; } cout << endl; } int main () int n; cin >> n; int m[n], tmp[n]; for (int i; i < n; i++){ cin >> m[i]; } for (int i = 0 ; i < n; i++){ tmp[i] = m[i]; } insert_sort (tmp, n); for (int i = 0 ; i < n; i++){ tmp[i] = m[i]; } shell_sort_onetime (tmp, n); for (int i = 0 ; i < n; i++){ tmp[i] = m[i]; } select_sort (tmp, n); for (int i = 0 ; i < n; i++){ tmp[i] = m[i]; } start_quick_sort (tmp, n); for (int i = 0 ; i < n; i++){ tmp[i] = m[i]; } twomerge_onetime (tmp, n); return 0 ; }
国名排序
第一行为一个n(n<=100)表示n个国家,第2行到第n+1行分别为n个国家的名字.
输出n个国家按字典顺序的排列.
字符串比较用strcmp,但是需要用结构体,不能用二维数组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <bits/stdc++.h> using namespace std;struct country { char name[100 ]; }s[100 ]; bool compare (struct country a, struct country b) return strcmp (a.name, b.name) < 0 ; } int main () int n; cin >> n; for (int i = 0 ; i< n; i++){ cin >> s[i].name; } sort (s, s+n, compare);; for (int i = 0 ; i< n; i++){ cout << s[i].name << endl; } return 0 ; }
日志排序
有一个网络日志,记录了网络中计算任务的执行情况,每个计算任务对应一条如下形式的日志记录:
“hs_10000_p”是计算任务的名称, “2007-01-17
19:22:53,315”是计算任务开始执行的时间“年-月-日 时:分:秒,毫秒”,
“253.035(s)”是计算任务消耗的时间(以秒计) hs_10000_p 2007-01-17
19:22:53,315 253.035(s) 请你写一个程序,对日志中记录计算任务进行排序。
时间消耗少的计算任务排在前面,时间消耗多的计算任务排在后面。
如果两个计算任务消耗的时间相同,则将开始执行时间早的计算任务排在前面。
输入描述:
1 2 3 日志中每个记录是一个字符串,每个字符串占一行。最后一行为空行,表示日志结束。日志中最多可能有10000 条记录。 计算任务名称的长度不超过10 ,开始执行时间的格式是YYYY -MM -DD HH :MM :SS ,MMM ,消耗时间小数点后有三位数字。 计算任务名称与任务开始时间、消耗时间之间以一个或多个空格隔开,行首和行尾可能有多余的空格。
输出描述:
1 2 排序好的日志记录。每个记录的字符串各占一行。 输入的格式与输入保持一致,输入包括几个空格,你的输出中也应该包含同样多的空格。
读入数据的格式化处理,学到了以下几个东西:
string也能进行直接比较,char * 可以用strcmp比较
substr 分割string
strtod把char * 变成浮点数
string中数字比较会麻烦一些,比如"40" > "350",但是40 <
350.
但是不知道为啥只过了一半:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <bits/stdc++.h> using namespace std;struct task { string name; string t; string rt; float rt_; }tk[10000 ]; bool compare (struct task a, struct task b) if (a.rt_ == b.rt_) return a.t < b.t; else return a.rt_ < b.rt_; } int main () string s; int cnt = 0 ; while (getline (cin, s)){ if (s == "" ) break ; int len = s.size (); int i=0 , j=0 ; for (j = len-1 ; j > 0 ; j--){ if (s[j] != ' ' && s[j-1 ] == ' ' ){ tk[cnt].rt = s.substr (j, len-j); break ; } } int l2 = tk[cnt].rt.size (); char tmp[100 ]; strcpy (tmp, tk[cnt].rt.substr (0 , l2-3 ).c_str ()); tk[cnt].rt_ = strtod (tmpstrtod, NULL ); for (i = 0 ; i < j; i++){ if (s[i] == ' ' && s[i+1 ] != ' ' ){ tk[cnt].name = s.substr (0 , i+1 );; tk[cnt].t = s.substr (i+1 , j-i-1 ); } } cnt ++; } sort (tk, tk+cnt, compare); for (int i = 0 ; i < cnt; i++){ cout << tk[i].name << tk[i].t << tk[i].rt << endl; } return 0 ; }
字符串排序2
编写一个程序,将输入字符串中的字符按如下规则排序(一个测试用例可能包含多组数据,请注意处理)。
规则 1 :英文字母从 A 到 Z 排列,不区分大小写。
如,输入: Type 输出: epTy
规则 2 :同一个英文字母的大小写同时存在时,按照输入顺序排列。
如,输入: BabA 输出: aABb
规则 3 :非英文字母的其它字符保持原来的位置。
如,输入: By?e 输出: Be?y
样例:
输入:
A Famous Saying: Much Ado About Nothing(2012/8).
输出:
A aaAAbc dFgghh : iimM nNn oooos Sttuuuy (2012/8).
思路:字母单独存起来(规则三),然后按字母表排序(cmp),大小写按照输入顺序排即需要稳点排序(stable_sort)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <bits/stdc++.h> using namespace std;bool cmp (char a, char b) if ((islower (a) && islower (b)) || (isupper (a) && isupper (b))) return a < b; else if (tolower (a) != tolower (b)) return tolower (a) < tolower (b); else return false ; } int main () char s[1000 ]; while (gets (s)){ int len = strlen (s); char s_[1000 ]; int idx = 0 ; for (int i = 0 ; i < len; i++){ if (isalpha (s[i])) s_[idx++] = s[i]; } stable_sort (s_, s_+idx, cmp); idx = 0 ; for (int i = 0 ; i < len; i++){ if (isalpha (s[i])) s[i] = s_[idx++]; } puts (s); } return 0 ; }
字符串排序3
题目描述
先输入你要输入的字符串的个数。然后换行输入该组字符串。每个字符串以回车结束,每个字符串少于一百个字符。
如果在输入过程中输入的一个字符串为“stop”,也结束输入。
然后将这输入的该组字符串按每个字符串的长度,由小到大排序,按排序结果输出字符串。
输入描述:
1 字符串的个数,以及该组字符串。每个字符串以‘\n’结束。如果输入字符串为“stop”,也结束输入.
输出描述:
1 2 3 4 5 可能有多组测试数据,对于每组数据, 将输入的所有字符串按长度由小到大排序输出(如果有“stop”,不输出“stop”)。 根据输入的字符串个数来动态分配存储空间(采用new ()函数)。每个字符串会少于100 个字符。 测试数据有多组,注意使用while ()循环输入。
my:cin之后会在缓冲区剩一个,如果再使用读取一行的函数读取会把,得用cin.ignore()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <bits/stdc++.h> using namespace std;struct st { string s; int len; }; bool cmp (struct st a, struct st b) return a.len < b.len; } int main () int n; while (cin >> n){ cin.ignore (); struct st s[n]; int cnt = 0 ; char tmp[100 ]; for (int i = 0 ; i < n; i++){ gets (tmp); if (strcmp (tmp, "stop" ) == 0 ){ break ; } else { s[i].s = tmp; s[i].len = s[i].s.size (); cnt++; } } sort (s, s+cnt, cmp); for (int i = 0 ; i < cnt; i++){ cout << s[i].s << endl; } } return 0 ; }
奥运排序问题
题目描述
按要求,给国家进行排名。
输入输出格式
输入描述:
1 2 3 4 有多组数据。 第一行给出国家数N ,要求排名的国家数M,国家号从0 到N -1 。 第二行开始的N 行给定国家或地区的奥运金牌数,奖牌数,人口数(百万)。 接下来一行给出M个国家号。
输出描述:
1 2 3 4 5 6 排序有4 种方式: 金牌总数 奖牌总数 金牌人口比例 奖牌人口比例 对每个国家给出最佳排名排名方式 和 最终排名 格式为: 排名:排名方式 如果有相同的最终排名,则输出排名方式最小的那种排名,对于排名方式,金牌总数 < 奖牌总数 < 金牌人口比例 < 奖牌人口比例 如果有并列排名的情况,即如果出现金牌总数为 100,90,90,80 .则排名为1,2,2,4 . 每组数据后加一个空行。
我的方法是用结构体定义这四种排名的参数,id和rk也需要在里面,最后根据id在sort一遍。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 #include <bits/stdc++.h> using namespace std;struct country { int id; double gold_num; double prize_num; double gold_per_person; double prize_per_person; int rk[4 ]; }; bool cmp0 (struct country a, struct country b) return a.id < b.id; } bool cmp1 (struct country a, struct country b) return a.gold_num > b.gold_num; } bool cmp2 (struct country a, struct country b) return a.prize_num > b.prize_num; } bool cmp3 (struct country a, struct country b) return a.gold_per_person > b.gold_per_person; } bool cmp4 (struct country a, struct country b) return a.prize_per_person > b.prize_per_person; } int main () int cn, acn; while (cin >> cn >> acn){ if (acn == 0 ){ continue ; } struct country * cty = new struct country[cn]; int acn_id[acn]; for (int i = 0 ; i < cn; i++){ cty[i].id = i; double gold, prize, population; cin >> gold >> prize >> population; cty[i].gold_num = gold; cty[i].prize_num = prize; cty[i].gold_per_person = gold / population; cty[i].prize_per_person = prize / population; } for (int i = 0 ; i < acn; i++){ cin >> acn_id[i]; } sort (cty, cty+cn, cmp1); int rk = 1 ; cty[0 ].rk[0 ] = rk++; for (int i = 1 ; i < cn; i++){ if (cty[i].gold_num == cty[i-1 ].gold_num){ cty[i].rk[0 ] = cty[i-1 ].rk[0 ]; rk++; } else cty[i].rk[0 ] = rk++; } sort (cty, cty+cn, cmp2); rk = 1 ; cty[0 ].rk[1 ] = rk++; for (int i = 1 ; i < cn; i++){ if (cty[i].prize_num == cty[i-1 ].prize_num){ cty[i].rk[1 ] = cty[i-1 ].rk[1 ]; rk++; } else cty[i].rk[1 ] = rk++; } sort (cty, cty+cn, cmp3); rk = 1 ; cty[0 ].rk[2 ] = rk++; for (int i = 1 ; i < cn; i++){ if (cty[i].gold_per_person == cty[i-1 ].gold_per_person){ cty[i].rk[2 ] = cty[i-1 ].rk[2 ]; rk++; } else cty[i].rk[2 ] = rk++; } stable_sort (cty, cty+cn, cmp4); rk = 1 ; cty[0 ].rk[3 ] = rk++; for (int i = 1 ; i < cn; i++){ if (cty[i].prize_per_person == cty[i-1 ].prize_per_person){ cty[i].rk[3 ] = cty[i-1 ].rk[3 ]; rk++; } else cty[i].rk[3 ] = rk++; } stable_sort (cty, cty+cn, cmp0); int idx = 0 ; for (int i = 0 ; i < cn; i++){ if (cty[i].id == acn_id[idx]){ idx++; int min_rk = cty[i].rk[0 ], mrk_id = 1 ; for (int j = 1 ; j < 4 ; j++){ if (min_rk > cty[i].rk[j]){ min_rk = cty[i].rk[j]; mrk_id = j+1 ; } } printf ("%d:%d\n" , min_rk, mrk_id); } else continue ; } cout << endl; } return 0 ; }
查找
可以sort+二分,也可以用map(和python的dic有点类似)
查找 - 北邮
题目描述
读入一组字符串(待操作的),再读入一个int
n记录记下来有几条命令,总共有2中命令:1、翻转
从下标为i的字符开始到i+len-1之间的字符串倒序;2、替换
命中如果第一位为1,用命令的第四位开始到最后的字符串替换原读入的字符串下标
i 到
i+len-1的字符串。每次执行一条命令后新的字符串代替旧的字符串(即下一条命令在作用在得到的新字符串上)。
命令格式:第一位0代表翻转,1代表替换;第二位代表待操作的字符串的起始下标int
i;第三位表示需要操作的字符串长度int len。
输入输出格式
输入描述:
1 2 输入有多组数据。 每组输入一个字符串(不大于100 )然后输入n ,再输入n 条指令(指令一定有效)。
输出描述:
字符串操作,主要用substr
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <bits/stdc++.h> using namespace std; int main () string str; while (cin >> str){ int n; cin >> n; string opt, tmp, r; int choice, start, len; for (int i = 0 ; i < n; i++){ cin >> opt; choice = opt[0 ] - '0' ; start = opt[1 ] - '0' ; len = opt[2 ] - '0' ; if (choice == 0 ){ tmp = str.substr (start, len); reverse (tmp.begin (), tmp.end ()); r = str.substr (0 , start) + tmp + str.substr (start+len); str = r; cout << str << endl; } else { tmp = opt.substr (3 ); r = str.substr (0 , start) + tmp + str.substr (start+len); str = r; cout << str << endl; } } } return 0 ; }
贪心算法
当前最优,常用sort。
喝饮料
题目描述
商店里有n中饮料,第i种饮料有mi毫升,价格为wi。
小明现在手里有x元,他想吃尽量多的饮料,于是向你寻求帮助,怎么样买才能吃的最多。
请注意,每一种饮料都可以只买一部分。
输入输出格式
输入描述:
1 2 3 4 5 有多组测试数据。 第一行输入两个非负整数x和n 。 接下来n 行,每行输入两个整数,分别为mi和wi。 所有数据都不大于1000 。 x和n 都为-1 时程序结束。
输出描述:
1 请输出小明最多能喝到多少毫升的饮料,结果保留三位小数。
找出单位价格最多饮料的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <bits/stdc++.h> using namespace std; struct drink { double m, w; }; bool cmp (struct drink a, struct drink b) return (a.m / a.w) > (b.m / b.w); } int main () double x; int n; while (cin >> x >> n){ if (x == -1 && n == -1 ) break ; else { struct drink dk[n]; for (int i = 0 ; i < n; i++){ cin >> dk[i].m >> dk[i].w; } sort (dk, dk+n, cmp); double r = 0 ; int idx = 0 ; while (x && idx < n){ if (x > dk[idx].w){ x -= dk[idx].w; r += dk[idx].m; idx++; } else { r += dk[idx].m / dk[idx].w * x; x = 0 ; break ; } } printf ("%.3lf\n" , r); } } return 0 ; }
链表
猴子报数
题目描述
n个猴子围坐一圈并按照顺时针方向从1到n编号,从第s个猴子开始进行1到m的报数,报数到第m的猴子退出报数,从紧挨它的下一个猴子重新开始1到m的报数,如此进行下去知道所有的猴子都退出为止。求给出这n个猴子的退出的顺序表。
输入输出格式
输入描述:
1 有做组测试数据.每一组数据有两行,第一行输入n(表示猴子的总数最多为100 )第二行输入数据s (从第s个猴子开始报数)和数据m (第m个猴子退出报数).当输入0 0 0时表示程序结束.
输出描述:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #include <bits/stdc++.h> using namespace std; struct node { int num; struct node *next; }; struct node *setup (int n){ struct node *head, *tmp, *pre; for (int i = 1 ; i <= n; i++){ tmp = (struct node *)malloc (sizeof (node)); if (i == 1 ){ head = tmp; pre = tmp; } tmp->num = i; tmp->next = head; pre->next = tmp; pre = tmp; } return head; } void print (struct node *head, int n, int s, int m) struct node *p, *pre; p = head; s--; while (s){ pre = p; p = p->next; s--; } int i = 1 ; while (true ){ if (p == p->next){ cout << p->num << endl; break ; } else { if (i % m == 0 ){ cout << p->num << "," ; pre->next = p->next; } else pre = p; p = p->next; i++; } } } int main () int n, s, m; while (cin >> n >> s >> m){ if (n == 0 && s == 0 && m == 0 ) break ; else { struct node *head; head = setup (n); print (head, n, s, m); } } return 0 ; }
单链表
题目描述
设节点定义如下
1 2 3 4 struct Node { int Element; struct Node * Next; };
从键盘输入5个整数,将这些整数插入到一个链表中,并按从小到大次序排列,最后输出这些整数。
直接插入,边插入边比较就行了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <bits/stdc++.h> using namespace std; struct Node { int Element; struct Node * Next; }; int main () struct Node *head = (struct Node*)malloc (sizeof (Node)); head->Next = NULL ; struct Node *p; for (int i = 0 ; i < 5 ; i++){ p = head; struct Node *tmp = (struct Node*)malloc (sizeof (Node)); cin >> tmp->Element; while (p->Next!=NULL ){ if (tmp->Element < p->Next->Element){ break ; } p = p->Next; } tmp->Next = p->Next; p->Next = tmp; } head = head->Next; while (head != NULL ){ cout << head->Element << " " ; head = head->Next; } cout << endl; return 0 ; }
链表合并
题目描述
给定两个元素有序(从小到大)的链表,要求将两个链表合并成一个有序(从小到大)链表,
输入输出格式
输入描述:
1 2 3 4 第一行输入第一个链表的结点数S1 ,S1 <=100 。 第二行输入S1 个整数,两两之间用空格隔开。 第三行输入第二个链表的结点数S2 ,S2 <=100 。 第四行输入S2 个整数,两两之间用空格隔开。
输出描述:
1 输出合并之后的链表结果,两两之间用空格隔开,末尾没有空格。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 #include <bits/stdc++.h> using namespace std; struct node { int element; struct node * next; }; struct node *setup (int n){ struct node *head, *p; for (int i = 0 ; i < n; i++){ struct node *tmp = new node; cin >> tmp->element; if (i == 0 ){ head = tmp; p = head; } else { tmp->next = NULL ; p->next = tmp; p = p->next; } } return head; } void merge (struct node *head1, struct node *head2) struct node *head, *p; if (head1->element < head2->element){ head = head1; head1 = head1->next; } else { head = head2; head2 = head2->next; } p = head; while (head1 != NULL && head2 != NULL ){ if (head1->element < head2->element){ p->next = head1; head1 = head1->next; } else { p->next = head2; head2 = head2->next; } p = p->next; } while (head1 != NULL ){ p->next = head1; head1 = head1->next; p = p->next; } while (head2 != NULL ){ p->next = head2; head2 = head2->next; p = p->next; } p = head; while (p != NULL ){ cout << p->element << " " ; p = p->next; } cout << endl; } int main () int n, m; cin >> n; struct node *head1, *head2; head1 = setup (n); cin >> m; head2 = setup (m); merge (head1, head2); return 0 ; }
数学
记住一些常见的,gcd,lcm, 斐波那契数列
素数
记录一下欧拉筛,用到了vector结构,并且进行函数传参;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 c++ #include <bits/stdc++.h> using namespace std;const int MAXN = 1020 ;bool isnp[MAXN];void init (int n, vector<int > &primes) for (int i = 2 ; i <= n; i++) { if (!isnp[i]) primes.push_back (i); for (int j = 0 ; j < primes.size (); j++){ int p = primes[j]; if (p * i > n) break ; isnp[p * i] = 1 ; if (i % p == 0 ) break ; } } } int main () int a, b; while (cin >> a >> b){ if (a > b){ int tmp = a; a = b; b = tmp; } vector<int > primes; init (b, primes); int cnt = 0 ; for (int j = 0 ; j < primes.size (); j++){ int p = primes[j]; if (p >= a && p <= b){ cnt++; } } cout << cnt << endl; } return 0 ;
质因数个数
题目描述
求正整数N(N>1)的质因数的个数。
相同的质因数需要重复计算。如120=22235,共有5个质因数。
输入输出格式
输入描述:
1 可能有多组测试数据,每组测试数据的输入是一个正整数N ,(1 <N <10 ^9 )。
输出描述:
虽然输入范围是1e9,但是实际上要求出来的素数范围不到1e5,还是可以用欧拉筛的,之后用素数表一个个试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <bits/stdc++.h> using namespace std;const int MAXN = 10000000 ;bool isnp[MAXN];void init (int n, vector<int > &primes) for (int i = 2 ; i <= n; i++) { if (!isnp[i]) primes.push_back (i); for (int j = 0 ; j < primes.size (); j++){ int p = primes[j]; if (p * i > n) break ; isnp[p * i] = 1 ; if (i % p == 0 ) break ; } } } int main () int n; while (cin >> n){ if (n < 4 ){ cout << 1 << endl; continue ; } vector<int > primes; int m = sqrt (n); init (m, primes); int cnt = 0 ; for (int i = 0 ; i < primes.size (); i++){ while (n % primes[i] == 0 ){ n /= primes[i]; cnt++; } } if (n > 1 ) cnt++; cout << cnt << endl; } return 0 ; }
最大素因子
题目描述
对于给定的字符序列,从左至右将所有的数字字符取出拼接成一个无符号整数(字符序列长度小于100,拼接出的整数小于2^31,),计算并输出该整数的最大素因子(如果是素数,则其最大因子为自身)
输入输出格式
输入描述:
1 有多组数据,输入数据的第一行为一个正整数,表示字符序列的数目,每组数据为一行字符序列。
输出描述:
1 对每个字符序列,取出所得整数的最大素因子,若字符序列中没有数字或者找出的整数为0,则输出0,每个整数占一行输出。
先处理字符串获得数字n,再得到&&\sqrt(n)&&以内的素数,然后遍历一遍得到最大素数;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <bits/stdc++.h> using namespace std;const int MAX = 0x7ffffff ;bool isp[MAX];void init (int n, vector<int > &primes) for (int i = 2 ; i < n; i++){ if (!isp[i]){ primes.push_back (i); } for (int j = 0 ; j < primes.size (); j++){ int p = primes[j]; if (p * i > n){ break ; } isp[p*i] = 1 ; if (i % p == 0 ){ break ; } } } } int deal_str (string s) int len = s.size (), r = 0 ; for (int i = 0 ; i < len; i++){ int tmp = s[i] - '0' ; if (tmp >= 0 && tmp <= 9 ){ r = r*10 + tmp; } } return r; } int main () int n; while (cin >> n){ string s; for (int i = 0 ; i < n; i++){ cin >> s; int n = deal_str (s); if (n == 0 ){ cout << 0 << endl; continue ; } int m = sqrt (n); vector<int > primes; init (m, primes); int p = 0 ; for (int j = 0 ; j < primes.size (); j++){ while (n % primes[j] == 0 ){ n /= primes[j]; if (primes[j] > p) p = primes[j]; } } if (n != 1 && n > p) p = n; cout << p << endl; } } return 0 ; }
精度
大整数加法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <bits/stdc++.h> using namespace std;#define max(a, b) (a > b ? a:b) #define min(a, b) (a < b ? a:b) string add (string a, string b) { int n1 = a.size (), n2 = b.size (); string r; int k = 0 ; for (int i = 0 ; i < n2; i++){ int tmp = (a[i] - '0' ) + (b[i] - '0' ) + k; r += (tmp) % 10 + '0' ; k = tmp / 10 ; } for (int i = n2; i < n1; i++){ int tmp = (a[i] - '0' ) + k; r += tmp % 10 + '0' ; k = tmp / 10 ; } if (k) r += k+'0' ; return r; } int main () string a, b; while (cin >> a >> b){ string r; reverse (a.begin (), a.end ()); reverse (b.begin (), b.end ()); if (a.size () > b.size ()){ r = add (a, b); } else { r = add (b, a); } reverse (r.begin (), r.end ()); cout << r << endl; } return 0 ; }
大整数乘法
先变成数字的数组,再算,然后进位
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include<bits/stdc++.h> using namespace std;int main(){ int n; string a, b; while (cin >> n >> a >> b){ reverse(a.begin (), a.end ()); reverse(b.begin (), b.end ()); int aa[105 ], bb[105 ], r[210 ] = {0 }; for (int i = 0 ; i < n; i++){ aa[i] = a[i] - '0' ; } for (int i = 0 ; i < n; i++){ bb[i] = b[i] - '0' ; } for (int i = 0 ; i < n; i++){ for (int j = 0 ; j < n; j++){ r[i+j] += aa[i] * bb[j]; } } int len = 2 *n; for (int i = 1 ; i < len; i++){ r[i] += r[i-1 ] / 10 ; r[i-1 ] %= 10 ; } while (!r[len]) len for (int i = len; i >= 0 ; i cout << r[i]; } cout << endl; } return 0 ; }
数据结构
栈
#include<stack\> 然后可以直接用了,常用的方法有.push .pop .top .empty
括号匹配
题目描述
假设表达式中允许包含两种括号:圆括号和方括号。编写一个算法判断表达式中的括号是否正确配对。
输入输出格式
输入描述:
1 由括号构成的字符串,包含”(“、”)“、”[“和”] “。
输出描述:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <bits/stdc++.h> using namespace std;int main () char s[100 ]; while (cin >> s){ stack<char > st; for (int i = 0 ; i < strlen (s); i++){ if (!st.empty ()){ char now = st.top (); if (s[i] == ')' &&now == '(' || s[i] == ']' &&now == '[' ){ st.pop (); } else { st.push (s[i]); } } else { st.push (s[i]); } } if (st.empty ()){ cout << "YES" << endl; } else { cout << "NO" <<endl; } } return 0 ; }
括号的匹配
题目描述
题意描述: 在算术表达式中,除了加、减、乘、除等运算外,往往还有括号。包括有大括号{},中括号[],小括号(),尖括号<>等。 对于每一对括号,必须先左边括号,然后右边括号;如果有多个括号,则每种类型的左括号和右括号的个数必须相等;对于多重括号的情形,按运算规则,从外到内的括号嵌套顺序为:大括号->中括号->小括号->尖括号。例如,{[()]},{()},{{}}为一个合法的表达式,而([{}]),{([])},[{<>}]都是非法的。
输入输出格式
输入描述:
1 文件的第一行为一个整数n (1 ≤n ≤100 ),接下来有n 行仅由上述四类括号组成的括号表达式。第i+1 行表示第i个表达式。每个括号表达式的长度不超过255 。
和上一题比较像,只不过给括号之间加入了优先级,判断一下就行
输出描述:
1 在输出文件中有N 行,其中第I 行对应第I 个表达式的合法性,合法输出YES ,非法输出NO 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <bits/stdc++.h> using namespace std;int main () int n; while (cin >> n){ for (int i = 0 ; i < n; i++){ string s; cin >> s; stack<char > st; for (int j = 0 ; j < s.size (); j++){ if (!st.empty ()){ char now = st.top (); if (now == '<' && (s[j] == '(' || s[j] == '[' || s[j] == '{' )) break ; if (now == '(' && (s[j] == '{' || s[j] == '[' )) break ; if (now == '[' && s[j] == '{' ) break ; if (now == '{' && s[j] == '}' || now == '[' && s[j] == ']' ||now == '(' && s[j] == ')' ||now == '<' && s[j] == '>' ){ st.pop (); } else { st.push (s[j]); } } else { st.push (s[j]); } } if (st.empty ()){ cout << "YES" << endl; } else { cout << "NO" << endl; } } } return 0 ; }
括号匹配问题
题目描述
在某个字符串(长度不超过100)中有左括号、右括号和大小写字母;规定(与常见的算数式子一样)任何一个左括号都从内到外与在它右边且距离最近的右括号匹配。写一个程序,找到无法匹配的左括号和右括号,输出原来字符串,并在下一行标出不能匹配的括号。不能匹配的左括号用"$"标注,不能匹配的右括号用"?"标注。
输入输出格式
输入描述:
1 2 输入包括多组数据,每组数据一行,包含一个字符串,只包含左右括号和大小写字母,字符串长度不超过100 。 注意:cin.getline(str ,100 )最多只能输入99 个字符!
输出描述:
1 对每组输出数据,输出两行,第一行包含原始输入字符,第二行由"$ " ,"?" 和空格组成,"$ " 和"?" 表示与之对应的左括号和右括号不能匹配。
先正序,再倒序入栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <bits/stdc++.h> using namespace std;int main () string s; while (cin >> s){ int len = s.size (); int tag[len] = {0 }; stack<char > st; for (int i = 0 ; i < len; i++){ if (s[i] == '(' ){ st.push (s[i]); continue ; } if (s[i] == ')' ){ if (st.empty ()){ tag[i] = 1 ; } else { st.pop (); } } } while (!st.empty ()){ st.pop (); } cout << s<< endl; reverse (s.begin (), s.end ()); for (int i = 0 ; i < len; i++){ if (s[i] == ')' ){ st.push (s[i]); continue ; } if (s[i] == '(' ){ if (st.empty ()){ tag[len - 1 - i] = 2 ; } else { st.pop (); } } } for (int i = 0 ; i < len; i++){ if (tag[i] == 0 ){ cout<<" " ; } else if (tag[i] == 1 ){ cout << "?" ; } else { cout << "$" ; } } cout << endl; } return 0 ; }
哈夫曼树
合并果子
题目描述
在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。多多决定把所有的果子合成一堆。
每一次合并,多多可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。可以看出,所有的果子经过n-1次合并之后,就只剩下一堆了。多多在合并果子时总共消耗的体力等于每次合并所耗体力之和。
因为还要花大力气把这些果子搬回家,所以多多在合并果子时要尽可能地节省体力。假定每个果子重量都为1,并且已知果子的种类数和每种果子的数目,你的任务是设计出合并的次序方案,使多多耗费的体力最少,并输出这个最小的体力耗费值。
例如有3种果子,数目依次为1,2,9。可以先将1、2堆合并,新堆数目为3,耗费体力为3。接着,将新堆与原先的第三堆合并,又得到新的堆,数目为12,耗费体力为12。所以多多总共耗费体力=3+12=15。可以证明15为最小的体力耗费值。
输入输出格式
输入描述:
1 输入包括两行,第一行是一个整数n (1 <=n<=10000 ),表示果子的种类数。第二行包含n个整数,用空格分隔,第i 个整数ai (1 <=ai<=20000 )是第i 种果子的数目。
输出描述:
1 输出包括一行,这一行只包含一个整数,也就是最小的体力耗费值。输入数据保证这个值小于 2 ^31 。
题目很容易看出贪心策略:每次只合并最小的两堆
但是每次合并后的堆还要放回去,得保证放回去后数据依旧有序
这里介绍一种数据结构:优先队列,头文件#include
<queue>
这个队列弹出元素不是按照入队的先后,而是按照权值的大小出队。
定义:
priority_queue <int> q;
定义队列q,权值大的先出队
priority_queue <int, vector <int>, greater
<int> > q;权值小的先出队
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <bits/stdc++.h> using namespace std;int main () int n; cin >> n; priority_queue<int , vector<int >, greater<int > > q; int a, ans = 0 ; for (int i = 0 ; i < n; i++){ cin >> a; q.push (a); } while (q.size () > 1 ){ int t1 = q.top (); q.pop (); int t2 = q.top (); q.pop (); int t = t1 + t2; q.push (t); ans += t; } cout << ans; return 0 ; }
其实还有一种写法,自己定义节点和操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <iostream> #include <queue> using namespace std;struct node { int x; bool operator < (const node& a) const { return x > a.x; } }; int main () int n, x; while (scanf ("%d" , &n) != EOF) { priority_queue<node> q; while (n--) { cin >> x; q.push (node{x}); } int ans = 0 ; while (q.size () > 1 ) { node num1 = q.top (); q.pop (); node num2 = q.top (); q.pop (); ans += num1.x + num2.x; q.push (node{num1.x + num2.x}); } cout << ans << endl; } }
哈夫曼编码
题目描述
熵编码器是一种数据编码方法,它通过对删除了“浪费”或“多余”信息的消息进行编码来实现无损数据压缩。换句话说,熵编码首先删除了对消息进行精确编码所不需要的信息。高度的熵意味着一条带有大量浪费信息的消息。以ASCII编码的英文文本是具有非常高的熵的消息类型的示例。已经压缩的消息(例如JPEG图形或ZIP归档文件)的熵很小,因此无法从进一步的熵编码尝试中受益。
用ASCII编码的英文文本具有很高的熵,因为所有字符都使用相同的位数(八位)进行编码。众所周知的事实是,与英语文本中大多数其他字母相比,字母E,L,N,R,S和T的出现频率要高得多。如果可以找到一种仅用4位对这些字母进行编码的方法,则新的编码将更小,包含所有原始信息并且熵更少。
ASCII会使用固定位数,这是有原因的:这很容易,因为一个人总是处理固定位数来表示每个可能的字形或字符。对于上述字母使用四位的编码方案如何区分四位代码和八位代码?使用所谓的“无前缀可变长度”编码可以解决这个看似困难的问题。
在这种编码中,可以使用任意数量的位来表示任何字形,并且消息中不存在的字形也不会被简单地编码。但是,为了能够恢复信息,不允许将编码字形的位模式作为任何其他编码位模式的前缀。这允许对编码的比特流进行逐位读取,并且只要遇到代表字形的一组位,就可以对该字形进行解码。如果没有实施无前缀约束,那么这样的解码将是不可能的。
考虑文字“
AAAAABCD”。使用ASCII,对此进行编码将需要64位。相反,如果我们用位模式“
00”编码“ A”,用“ 01”编码“ B”,用“ 10”编码“ C”,用“ 11”编码“
D”,那么我们只能用16位编码该文本。位;结果位模式将为“
0000000000011011”。但是,这仍然是固定长度的编码。每个字形使用的是两位,而不是八位。由于字形“
A”以更高的频率出现,我们可以通过用更少的比特对其进行编码来做得更好吗?实际上我们可以,但是为了保持无前缀编码,其他一些位模式将变得比两位长。最佳编码是用“
0”编码“ A”,用“ 10”编码“ B”,用“ 110”编码“ C”,用“ 111”编码“ D”。
(这显然不是唯一的最佳编码,因为很明显,对于B,C和D的编码可以在不增加最终编码消息大小的情况下自由地互换用于任何给定的编码。)使用这种编码,消息可以在“
0000010110111”只有13位,压缩比为4.9:1(也就是说,最终编码消息中的每个位代表的信息与原始编码中4.9位的信息一样多)。从左到右通读此位模式,您会发现,即使代码的位长不同,无前缀编码也可以很容易地将其解码为原始文本。
作为第二个示例,请考虑文字“帽子里的猫”。在本文中,字母“
T”和空格字符均以最高频率出现,因此在最佳编码中,它们显然具有最短的编码位模式。字母“
C”,“ I”和“ N”仅出现一次,因此它们的编码最长。
有许多可能的无前缀可变长度位模式集,它们可以产生最佳编码,也就是说,允许文本以最少的位数进行编码。一种这样的最佳编码是使用“
00”,“ A”和“ 100”,“ C”和“ 1110”,“ E”和“ 1111”,“ H”和“ 110”,“ I”和“
1010”,“ N”和“ 1011”以及“ T”和“
01”。因此,最佳编码仅需要51位,而使用144位消息以8位ASCII编码(压缩率为2.8到1)进行编码时则需要144位。
输入输出格式
输入描述:
1 输入文件将包含文本字符串列表,每行一个。 文本字符串将仅包含大写字母数字字符和下划线(用于代替空格)。 输入结束将通过仅包含单词“ END ”作为文本字符串的行来表示。 此行不应被处理。
输出描述:
1 对于输入中的每个文本字符串,输出8 位ASCII 编码的位长度,最佳无前缀可变长度编码的位长度以及精确到小数点后的压缩率。
只求哈夫曼编码的长度可以规约到以字符的数量大小为叶节点的哈夫曼树上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <bits/stdc++.h> using namespace std;int main () string s; while (cin >> s){ if (s == "END" ){ break ; } else { map<char , int > m; int len = s.size (); for (int i = 0 ; i < len; i++){ m[s[i]]++; } map<char , int >::iterator iterm; priority_queue<int , vector<int >, greater<int > > q; for (iterm = m.begin (); iterm != m.end (); iterm++){ q.push (iterm->second); } int ans = 0 ; if (q.size () == 1 ){ ans = q.top (); } while (q.size () > 1 ){ int t1 = q.top (); q.pop (); int t2 = q.top (); q.pop (); int t3 = t1 + t2; ans += t3; q.push (t3); } int l = len * 8 ; printf ("%d %d %.1f\n" , l, ans, (double )l / ans); } } return 0 ; }
二叉树
一些概念:二叉树定义、特点、性质:
其他的概念比如满二叉树、完全二叉树,二叉树遍历(前中后序)
二叉树的建立和遍历
题目描述
建立以二叉链作为存储结构的二叉树,实现 1)先序遍历; 2)中序遍历;
3)后序遍历; 4)层序遍历; 5)编程计算二叉树的叶子结点个数。
输入输出格式
输入描述:
1 按照先序遍历序列输入二叉树中数据元素的值,没有的输入0表示。
输出描述:
1 第一行输出先序遍历序列 第二行输出中序遍历序列 第三行输出后序遍历序列 第四行输出叶子结点的个数。
注意函数传参
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 #include <bits/stdc++.h> using namespace std;#define max(a, b) a > b ? a : b; typedef struct node { char c; struct node *l, *r; }*Tree; void createTree (Tree &T) char c; cin >> c; if (c == '0' ){ T = NULL ; } else { T = (struct node *)malloc (sizeof (node)); T->c = c; createTree (T->l); createTree (T->r); } } void PreOrderTraverse (Tree T) if (T != NULL ){ cout << T->c << " " ; PreOrderTraverse (T->l); PreOrderTraverse (T->r); } else { return ; } } void InOrderTraverse (Tree T) if (T != NULL ){ InOrderTraverse (T->l); cout << T->c << " " ; InOrderTraverse (T->r); } } void PostOrderTraverse (Tree T) if (T != NULL ){ PostOrderTraverse (T->l); PostOrderTraverse (T->r); cout << T->c << " " ; } } int Leaf (Tree T) if (T == NULL ) return 0 ; else if (T->l == NULL && T->r == NULL ) return 1 ; return Leaf (T->l) + Leaf (T->r); } int Depth (Tree T) if (T == NULL ) return 0 ; int x = Depth (T->l); int y = Depth (T->r); return max (x, y) + 1 ; } int main () Tree root; createTree (root); PreOrderTraverse (root); cout << endl; InOrderTraverse (root); cout << endl; PostOrderTraverse (root); cout << endl; cout << Leaf (root) << endl; return 0 ; }
二叉树遍历
题目描述
编一个程序,读入用户输入的一串先序遍历字符串,根据此字符串建立一个二叉树(以指针方式存储)。
例如如下的先序遍历字符串: ABC##DE#G##F###
其中“#”表示的是空格,空格字符代表空树。建立起此二叉树以后,再对二叉树进行中序遍历,输出遍历结果
输入输出格式
输入描述:
输出描述:
1 2 3 可能有多组测试数据,对于每组数据, 输出将输入字符串建立二叉树后中序遍历的序列,每个字符后面都有一个空格。 每个输出结果占一行。
注意create的时候,new出来的tree空间是在堆上,和栈一样要初始化(但我也不知道为什么上一题不用也可以),总之初始化一定不会有问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <bits/stdc++.h> using namespace std;typedef struct node { char c; struct node *l, *r; } *Tree; int idx;string s; void create (Tree &T) if (idx >= s.size ()) return ; char c = s[idx++]; if (c == '#' ){ T = NULL ; } else { T = new node; T->c = c; T->l = NULL ; T->r = NULL ; create (T->l); create (T->r); } } void InOrderTraverse (Tree T) if (T != NULL ){ InOrderTraverse (T->l); cout << T->c << " " ; InOrderTraverse (T->r); } } int main () while (cin >> s){ idx = 0 ; Tree root; create (root); InOrderTraverse (root); printf ("\n" ); } return 0 ; }
二叉树
题目描述
1
/
2 3
/ \ /4 5 6 7 / / / / 如上图所示,由正整数 1, 2, 3,
...组成了一棵无限大的二叉树。从某一个结点到根结点(编号是1的结点)都有一条唯一的路径,比如从5到根结点的路径是(5,
2, 1),从4到根结点的路径是(4, 2,
1),从根结点1到根结点的路径上只包含一个结点1,因此路径就是(1)。对于两个结点x和y,假设他们到根结点的路径分别是(x1,
x2, ... ,1)和(y1, y2,...,1),那么必然存在两个正整数i和j,使得从xi
和yj 开始,有xi = yj,xi + 1 = yj + 1,xi + 2 = yj + 2,...
现在的问题就是,给定x和y,要求他们的公共父节点,即xi(也就是 yj)。
输入输出格式
输入描述:
1 输入包含多组数据,每组数据包含两个正整数x 和y(1 ≤x , y≤2 ^31 -1 )。
输出描述:
1 对应每一组数据,输出一个正整数xi ,即它们的首个公共父节点。
利用完全二叉树的特性,父节点 =子节点/2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <bits/stdc++.h> using namespace std;int main () int x, y; while (cin >> x >> y){ while (x!=y){ if (x > y){ x /=2 ; } else { y /= 2 ; } } cout << x << endl; } return 0 ; }
二叉树2
题目描述
如上所示,由正整数1,2,3……组成了一颗特殊二叉树。我们已知这个二叉树的最后一个结点是n。现在的问题是,结点m所在的子树中一共包括多少个结点。 比如,n = 12,m = 3那么上图中的结点13,14,15以及后面的结点都是不存在的,结点m所在子树中包括的结点有3,6,7,12,因此结点m的所在子树中共有4个结点。输入输出格式
输入描述:
1 输入数据包括多行,每行给出一组测试数据,包括两个整数m,n (1 <= m <= n <= 1000000000 )。
输出描述:
1 对于每一组测试数据,输出一行,该行包含一个整数,给出结点m所在子树中包括的结点的数目。
直接递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <bits/stdc++.h> using namespace std;int ans;void cal (int x, int y) if (x > y){ return ; } else { ans += 1 ; cal (x*2 , y); cal (x*2 +1 , y); } } int main () int x, y; while (cin >> x >> y){ ans = 0 ; cal (x, y); cout << ans << endl; } return 0 ; }
二叉树遍历2
题目描述
二叉树的前序、中序、后序遍历的定义:
前序遍历:对任一子树,先访问跟,然后遍历其左子树,最后遍历其右子树;
中序遍历:对任一子树,先遍历其左子树,然后访问根,最后遍历其右子树;
后序遍历:对任一子树,先遍历其左子树,然后遍历其右子树,最后访问根。
给定一棵二叉树的前序遍历和中序遍历,求其后序遍历(提示:给定前序遍历与中序遍历能够唯一确定后序遍历)。
输入输出格式
输入描述:
1 2 3 两个字符串,其长度n均小于等于26 。 第一行为前序遍历,第二行为中序遍历。 二叉树中的结点名称以大写字母表示:A ,B ,C....最多26 个结点。
输出描述:
1 2 输入样例可能有多组,对于每组测试样例, 输出一行,为后序遍历的字符串。
对前序来说,第一个永远是父节点;对中序来说,父节点将子节点分开。根据这个思路递归建树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <bits/stdc++.h> using namespace std;typedef struct node { char c; struct node *l, *r; }*Tree; int flag;Tree build (string pre, string mid, int start, int end) { if (start > end) return NULL ; int n; for (int i = start; i <= end; i++){ if (pre[flag] == mid[i]) n = i; } Tree t; t = new node; t->c = pre[flag]; t->l = NULL ; t->r = NULL ; flag++; t->l = build (pre, mid, start, n-1 ); t->r = build (pre, mid, n+1 , end); return t; } void PostOrderTraverse (Tree t) if (t!=NULL ){ PostOrderTraverse (t->l); PostOrderTraverse (t->r); cout << t->c; } } int main () string x, y; while (cin >> x >> y){ flag = 0 ; int len = y.size (); Tree root; root = build (x, y, 0 , len-1 ); PostOrderTraverse (root); cout << endl; } return 0 ; }
判断二叉树是否对称
题目描述
层次遍历的方式输入一个二叉树,判断这个二叉树的结构(即不用管结点的值)是否镜像对称。
输入输出格式
输入描述:
1 输入一行字母,其中#表示空节点(字母长度小于1000)。
输出描述:
1 如果输入的二叉树对称,输出YES ,否则输出NO 。
先层次读入二叉树,方法是用队列,先进的节点先读取;然后递归判断是否对称,即使用左右节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #include <bits/stdc++.h> using namespace std;typedef struct node { char c; struct node *l, *r; }*Tree; Tree build (string s) { int x = 0 ; queue<Tree> q; Tree root = new node; if (s[0 ] != '#' ){ root->c = s[x++]; root->l = NULL ; root->r = NULL ; q.push (root); } while (q.size ()){ Tree rt = q.front (); q.pop (); Tree l, r; if (s[x] == '#' ){ l = NULL ; } else { l = new node; l->c = s[x]; q.push (l); } x++; rt->l = l; if (s[x] == '#' ){ r = NULL ; } else { r = new node; r->c = s[x]; q.push (r); } x++; rt->r = r; } return root; } bool judge (Tree l, Tree r) if (l == NULL && r == NULL ) return true ; else if (l == NULL || r == NULL ) return false ; else { return judge (l->l, r->r) & judge (l->r, r->l); } } int main () string s; while (cin >> s){ Tree root; root = build (s); Tree l = root->l, r = root->r; bool ans = judge (l, r); if (ans) cout << "YES" << endl; else cout << "NO" << endl; } return 0 ; }
看别人写的也有直接对字符串进行对称判断的。第0-0个是第一层,1-2是第二层,3-6是第三层...,即i-j,下一层就是2i+1——2j+2,然后就简单了。奕
!悟!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <stdio.h> #include <math.h> #include <stdlib.h> #include <string.h> int Judge (char *s,int start,int end,int len) if (end>=len) { return 1 ; } for (int i = start,j=end; i<=j; i++,j--) { if ((s[i]=='#' &&s[j]!='#' )||(s[j]=='#' &&s[i]!='#' )) { return 0 ; } } return Judge (s,2 *start+1 ,2 *end+2 ,len); } int main () char s[1000 ]; int len; scanf ("%s" ,s); printf ("%s" ,Judge (s,0 ,0 ,strlen (s))?"YES" :"NO" ); return 0 ; }
二叉排序树
左子树的比根节点小,右子树比根节点大,左右子树也都是二叉排序树
二叉排序树2
题目描述
输入一系列整数,建立二叉排序树,并进行前序,中序,后序遍历。
输入输出格式
输入描述:
1 2 输入第一行包括一个整数n ()。 接下来的一行包括n 个整数。
输出描述:
1 2 3 4 可能有多组测试数据,对于每组数据,将题目所给数据建立一个二叉排序树,并对二叉排序树进行前序、中序和后序遍历。 每种遍历结果输出一行。每行最后一个数据之后有一个空格。 输入中可能有重复元素,但是输出的二叉树遍历序列中重复元素不用输出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #include <bits/stdc++.h> using namespace std;typedef struct node { int d; struct node *l, *r; } *Tree; void build (Tree &t, int a) if (t == NULL ){ t = new node; t->d = a; t->l = NULL ; t->r = NULL ; return ; } if (a == t->d) return ; if (a < t->d) build (t->l, a); else build (t->r, a); } void PreOrdertraverse (Tree t) if (t != NULL ){ cout << t->d << " " ; PreOrdertraverse (t->l); PreOrdertraverse (t->r); } } void MidOrdertraverse (Tree t) if (t != NULL ){ MidOrdertraverse (t->l); cout << t->d << " " ; MidOrdertraverse (t->r); } } void PostOrdertraverse (Tree t) if (t != NULL ){ PostOrdertraverse (t->l); PostOrdertraverse (t->r); cout << t->d << " " ; } } int main () int n; while (cin >> n){ Tree root; root = NULL ; int a; for (int i = 0 ; i < n; i++){ cin >> a; build (root, a); } PreOrdertraverse (root); cout << endl; MidOrdertraverse (root); cout << endl; PostOrdertraverse (root); cout << endl; } return 0 ; }
二叉搜索树
题目描述
判断两序列是否为同一二叉搜索树序列
输入输出格式
输入描述:
1 2 3 开始一个数n ,(1 <=n <=20 ) 表示有n 个需要判断,n = 0 的时候输入结束。 接下去一行是一个序列,序列长度小于10 ,包含(0 ~9 )的数字,没有重复数字,根据这个序列可以构造出一颗二叉搜索树。 接下去的n 行有n 个序列,每个序列格式跟第一个序列一样,请判断这两个序列是否能组成同一颗二叉搜索树。
输出描述:
我的方法是对每个序列建一个树,然后存储和其前序遍历字符串进行比较
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <bits/stdc++.h> using namespace std;typedef struct node { char d; struct node *l, *r; } *Tree; int a;void build (Tree &t, char a) if (t == NULL ){ t = new node; t->d = a; t->l = NULL ; t->r = NULL ; return ; } if (a == t->d) return ; if (a < t->d) build (t->l, a); else build (t->r, a); } void PreOrdertraverse (Tree t, string &s) if (t != NULL ){ s+= t->d; PreOrdertraverse (t->l, s); PreOrdertraverse (t->r, s); } } int main () int n; while (cin >> n){ if (n == 0 ) break ; Tree root; root = NULL ; string s, s0; cin >> s; for (int i = 0 ; i < s.size (); i++){ build (root, s[i]); } PreOrdertraverse (root, s0); for (int i = 0 ; i < n; i++){ string st; cin >> s; Tree rt; rt = NULL ; for (int j = 0 ; j < s.size (); j++){ build (rt, s[j]); } PreOrdertraverse (rt, st); if (st == s0){ cout << "YES" << endl; } else { cout << "NO" << endl; } } } return 0 ; }
看了下别人的方法,需要前序和中序才能确定一颗唯一的树,我只用了前序应该是有问题的,但测试用例应该里没有专门设计一个这样的用例233.
二叉排序树 - 华科
题目描述
二叉排序树,也称为二叉查找树。可以是一颗空树,也可以是一颗具有如下特性的非空二叉树:
1. 若左子树非空,则左子树上所有节点关键字值均不大于根节点的关键字值; 2.
若右子树非空,则右子树上所有节点关键字值均不小于根节点的关键字值; 3.
左、右子树本身也是一颗二叉排序树。
现在给你N个关键字值各不相同的节点,要求你按顺序插入一个初始为空树的二叉排序树中,每次插入后成功后,求相应的父亲节点的关键字值,如果没有父亲节点,则输出-1。
输入输出格式
输入描述:
1 2 3 输入包含多组测试数据,每组测试数据两行。 第一行,一个数字N (N <=100 ),表示待插入的节点数。 第二行,N 个互不相同的正整数,表示要顺序插入节点的关键字值,这些值不超过10 ^8 。
输出描述:
1 输出共N 行,每次插入节点后,该节点对应的父亲节点的关键字值。
边插入边找,递归的函数加一个参数作为根节点即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <bits/stdc++.h> using namespace std;typedef struct node { int d; struct node *l, *r; }*Tree; int build (Tree r, Tree &t, int a) int res; if (t == NULL ){ t = new node; t->d = a; t->l = NULL ; t->r = NULL ; return r->d; } if (a == t->d) res = r->d; else if (a < t->d) res = build (t, t->l, a); else res = build (t, t->r, a); return res; } int main () int n; while (cin >> n){ Tree tmp = new node; tmp->d = -1 ; Tree root; root = NULL ; int a[n]; for (int i = 0 ; i < n; i++){ cin >> a[i]; int x = build (tmp, root, a[i]); cout << x << endl; } } return 0 ; }
hash
统计同成绩学生人数
题目描述
读入N名学生的成绩,将获得某一给定分数的学生人数输出。
输入输出格式
输入描述:
1 2 3 4 5 6 7 8 测试输入包含若干测试用例,每个测试用例的格式为 第1 行:N 第2 行:N 名学生的成绩,相邻两数字用一个空格间隔。 第3 行:给定分数 当读到N =0 时输入结束。其中N 不超过1000 ,成绩分数为(包含)0 到100 之间的一个整数。
输出描述:
直接map
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <bits/stdc++.h> using namespace std;int main () int n; while (cin >> n){ if (n == 0 ) break ; int a[n], sn; map<int , int > m; for (int i = 0 ; i < n; i++){ cin >> a[i]; m[a[i]] ++; } cin >> sn; if (m.find (sn) != m.end ()){ cout << m[sn] << endl; } else { cout << 0 << endl; } } return 0 ; }
谁是你的潜在朋友
题目描述
“臭味相投”——这是我们描述朋友时喜欢用的词汇。两个人是朋友通常意味着他们存在着许多共同的兴趣。然而作为一个宅男,你发现自己与他人相互了解的机会并不太多。幸运的是,你意外得到了一份北大图书馆的图书借阅记录,于是你挑灯熬夜地编程,想从中发现潜在的朋友。 首先你对借阅记录进行了一番整理,把N个读者依次编号为1,2,…,N,把M本书依次编号为1,2,…,M。同时,按照“臭味相投”的原则,和你喜欢读同一本书的人,就是你的潜在朋友。你现在的任务是从这份借阅记录中计算出每个人有几个潜在朋友。输入输出格式
输入描述:
1 每个案例第一行两个整数N ,M,2 <= N ,M<= 200 。接下来有N 行,第i(i = 1 ,2 ,…,N )行每一行有一个数,表示读者i-1 最喜欢的图书的编号P(1 <=P<=M)
输出描述:
1 每个案例包括N行,每行一个数,第i 行的数表示读者i 有几个潜在朋友。如果i 和任何人都没有共同喜欢的书,则输出“BeiJu”(即悲剧,^ ^)
mapmap
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <bits/stdc++.h> using namespace std;int main () int n, m; while (cin >> n >> m){ map<int , int > mm; int a[n]; for (int i = 0 ; i < n; i++){ cin >> a[i]; mm[a[i]]++; } for (int i = 0 ; i < n; i++){ if (mm[a[i]] == 1 ){ cout << "BeiJu" << endl; } else cout << mm[a[i]] - 1 << endl; } } return 0 ; }
剩下的树
题目描述
有一个长度为整数L(1<=L<=10000)的马路,可以想象成数轴上长度为L的一个线段,起点是坐标原点,在每个整数坐标点有一棵树,即在0,1,2,...,L共L+1个位置上有L+1棵树。
现在要移走一些树,移走的树的区间用一对数字表示,如 100
200表示移走从100到200之间(包括端点)所有的树。
可能有M(1<=M<=100)个区间,区间之间可能有重叠。现在要求移走所有区间的树之后剩下的树的个数。
输入输出格式
输入描述:
1 2 两个整数L(1 <= L<= 10000 )和M(1 <= M<= 100 )。 接下来有M组整数,每组有一对数字。
输出描述:
1 可能有多组输入数据,对于每组输入数据,输出一个数,表示移走所有区间的树之后剩下的树的个数。
纯暴力的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> using namespace std;int main () int n, m; while (cin >> n >> m){ map<int , int > mm; int a[n+1 ]; for (int i = 0 ; i <= n; i++){ a[i] = 1 ; } int cnt = 0 , begin, end; for (int i = 0 ; i < m; i++){ cin >> begin >> end; for (int j = 0 ; j <= n; j++){ if (j >= begin && j <= end && a[j] == 1 ){ a[j] = 0 ; } } } for (int i = 0 ; i <= n; i++){ if (a[i] == 1 ) cnt ++; } cout << cnt << endl; } return 0 ; }
看了下别人的,有个方法叫差分数组,就是用一个数组维护原数组前一个对后一个的差,如果要统一修改[a,b]之间的值只需要在a、b两点修改差分数组就行了,复杂度只有on
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <bits/stdc++.h> using namespace std;int main () int n, m; while (cin >> n >> m){ int cnt = 0 ; vector<int > a (n+2 , 1 ) ; vector<int > d (n+2 , 0 ) ; int l, r; for (int i = 0 ; i < m; i++){ cin >> l >> r; l++; r++; d[l]--; d[r+1 ]++; } for (int i = 1 ; i < n+2 ; i++){ a[i] = d[i] + a[i-1 ]; } for (int i = 1 ; i < n+2 ; i++){ if (a[i] > 0 ) cnt ++; } cout << cnt << endl; } return 0 ; }
除了被改的区域一直--外,其他区域都恒为1
刷出一道墙
题目描述
在一面很长的墙壁上,工人们用不同的油漆去刷墙,然而可能有些地方刷过以后觉得不好看,他们会重新刷一下。有些部分因为重复刷了很多次覆盖了很多层油漆,小诺很好奇那些地方被刷过多少种颜色的油漆。
输入输出格式
输入描述:
1 2 3 4 若干行输入,每行两个数字B,E(0<=B<=E<=200000)表示这次刷的墙壁是哪一段 (假设每次刷的时候油漆颜色都和之前的不同),以0 0结束 又若干行输入,每行两个数字begin,end(0<=begin<=end<=200000)表示小诺询问的段, 以0 0结束
输出描述:
1 对于每个小诺的询问输出(end [i]-begin [i]+1 )行,表示对应询问段的每个点被多少种颜色的油漆覆盖过。
还是差分数组,不知道为啥我的一直过不了~试了改scanf和去掉cout的缓冲区都不行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> using namespace std;int main () int l, r, m = 0 ; vector<int > a (20005 , 0 ) ; vector<int > d (20005 , 0 ) ; while (scanf ("%d %d" , &l, &r) != EOF){ if (l == 0 && r == 0 ) break ; l++; r++; d[l]++; d[r+1 ]--; m = max (r, m); } for (int i = 1 ; i < m; i++){ a[i] = d[i] + a[i-1 ]; } while (scanf ("%d %d" , &l, &r) != EOF){ if (l == 0 && r == 0 ) break ; l++; r++; for (int i = l; i <= r; i++){ printf ("%d\n" , a[i]); } } return 0 ; }
前缀树
前缀字符串
题目描述
如果一个字符串s1是由另一个字符串s2的前面部分连续字符组成的,那么我们就说s1就是s2的前缀。比如“ac”是“acm”的前缀,“abcd”是“abcddfasf”的前缀,特别的“kdfa”是“kdfa”的前缀。
现在给你一些字符串,你的任务就是从这些字符串中找出一些字符串放到一个集合中,使得这个集合中任意一个字符串不是其他字符串的前缀,并且要使集合里的字符串尽可能的多。输出这个集合中字符串的个数。
输入输出格式
输入描述:
1 2 有多组测试数据。每组测试数据以一个整数n 开头,随后有n 个字符串。 当n =0 时表示输入结束。 0 <n <100 ,字符串长度不大于20 。
输出描述:
1 每组测试数据输出一个整数,即所求的最大值。每组数据占一行。
构建一颗前缀树,求它的叶子节点个数即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #include <bits/stdc++.h> using namespace std;const int maxn = 26 ;typedef struct node { int ct; struct node *next[maxn]; } *Tree; void initTree (Tree &r) r->ct = 0 ; for (int i = 0 ; i < maxn; i++){ r->next[i] = NULL ; } } void buildTree (Tree &r, string s) Tree p = r, q; int len = s.size (); for (int i = 0 ; i < len; i++){ int k = s[i] - 'a' ; if (p->next[k] == NULL ){ q = new node; q->ct = 1 ; for (int j = 0 ; j < maxn; j++){ q->next[j] = NULL ; } p->next[k] = q; p = p->next[k]; } else { p->next[k]->ct++; p = p->next[k]; } } } int countTree (Tree r) int sum = 0 ; queue<Tree> q; q.push (r); while (!q.empty ()){ Tree p = q.front (); q.pop (); int tmp = 0 ; for (int i = 0 ; i < maxn; i++){ if (p->next[i] == NULL ) tmp++; else q.push (p->next[i]); } if (tmp == maxn) sum++; } return sum; } int main () int n; while (cin >> n){ if (n == 0 ) break ; Tree root = new node; initTree (root); for (int i = 0 ; i < n; i++){ string s; cin >> s; buildTree (root, s); } int sum = countTree (root); cout << sum << endl; } return 0 ; }
但是这题的数据量很小,我们也可以用map来搞定,记得每次存长度最大的那个
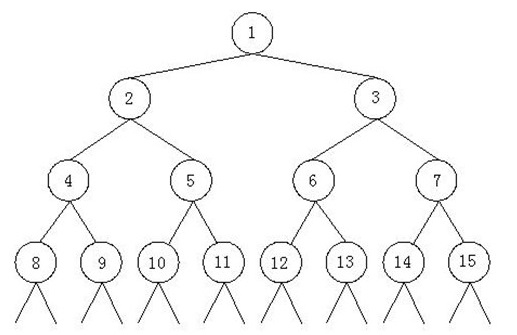
北邮2019 二叉树
题目描述
对二叉树,计算任意两个结点的最短路径长度。
输入输出格式
输入描述:
1 2 3 4 第一行输入测试数据组数 T 第二行输入 n , m 。 n 代表输入的数据组数, m 代表要查询的数据组数。 接下来 n 行,每行输入两个数,代表1 ~ n 结点的孩子结点,如果没有孩子结点则输入-1 ,根节点为1 。 接下来 m 行,每行输入两个数,代表要查询的两个结点。
输出描述:
1 每组测试数据输出 m 行,代表查询的两个结点之间的最短路径长度。
找最小公共祖先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <bits/stdc++.h> using namespace std;const int maxn = 10000 ;int f[maxn];vector<int > findminipath (int a) { vector<int > res; while (f[a] != 1 ){ res.push_back (a); a = f[a]; } res.push_back (a); if (a != 1 ) res.push_back (1 ); return res; } int main () int t, n, m; cin >> t; for (int i = 0 ; i < t; i++){ cin >> n >> m; f[1 ] = 1 ; int l, r; for (int j = 0 ; j < n; j++){ cin >> l >> r; if (l != -1 ){ f[l] = j+1 ; } if (r != -1 ){ f[r] = j+1 ; } } for (int j = 0 ; j < m; j++){ cin >> l >> r; vector<int > lp = findminipath (l); vector<int > rp = findminipath (r); int idx1=lp.size () - 1 , idx2 = rp.size () - 1 ; for (;idx1>=0 , idx2>=0 ; idx1--, idx2--){ if (lp[idx1] != rp[idx2]){ break ; } } cout << idx1+idx2+2 << endl; } } return 0 ; }
有向树形态
题目描述
求N个结点能够组成的二叉树的个数。 1<=n<=20
输入输出格式
输入描述:
输出描述:
卡特兰数,n较小直接递推,加上记忆化搜索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <bits/stdc++.h> using namespace std;long long a[25 ];int main () int n; cin >> n; a[0 ] = 1 , a[1 ] = 1 ; for (int i = 2 ; i <= n; i++){ long long ans = 0 ; for (int j = 0 ; j < i; j++){ ans += a[j] * a[i-j-1 ]; } a[i] = ans; } cout << a[n] << endl; return 0 ; }
南京理工-树的高度
题目描述
树是一种特殊的图结构,有根树是一个有固定根的树。现在给定一棵有根树,编程求出树中所有节点到指定的根节点最远距离。
输入输出格式
输入描述:
1 第一行是两个整数N ,M(1 <=N <=10000 ,1 <=M<=N ),表示数的顶点数和根节点的编号,接下来N -1 行,每行两个整数u,v(1 <=u,v<=N ),表示编号为u的节点和编号为v的节点间有一条边。
输出描述:
BFS算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <bits/stdc++.h> using namespace std;struct node { vector<int >edge; int deep; bool visit; node (){ deep = 0 ; visit = false ; } }; int main () int n, m; cin >> n >> m; node nod[10000 ]; queue<int > q; int u, v; for (int i = 0 ; i < n-1 ; i++){ cin >> u >> v; nod[u].edge.push_back (v); nod[v].edge.push_back (u); } int max = 1 ; nod[m].deep = 1 ; nod[m].visit = true ; q.push (m); while (!q.empty ()){ int now = q.front (); q.pop (); for (int i = 0 ; i < nod[now].edge.size (); i++){ if (!nod[nod[now].edge[i]].visit){ nod[nod[now].edge[i]].visit = true ; nod[nod[now].edge[i]].deep = nod[now].deep + 1 ; if (max < nod[nod[now].edge[i]].deep) max = nod[nod[now].edge[i]].deep; q.push (nod[now].edge[i]); } } } cout << max - 1 << endl; return 0 ; }
搜索
迷宫
题目描述
Time Limit: 1000 ms Memory Limit: 256 mb
小 A 同学现在被困在了一个迷宫里面,他很想从迷宫中走出来,他可以
向上、向下、向左、向右移动、每移动一格都需要花费 1 秒的时间,不能够走到
边界之外。假设小 A 现在的位置在 S,迷宫的出口在 E,迷宫可能有多个出口。
问小 A 想要走到迷宫出口最少需要花费多少秒?
输入输出格式
输入描述:
1 2 3 4 5 6 有多组测试数据。 第一行输入两个正整数 H (0 < H <= 100 )和 W(0 < W <= 100 ),分别表示迷 宫的高和宽。 接下来 H 行,每行 W 个字符(其中‘*’表示路,‘ 的位置,‘E’表示迷宫出口)。 当 H 与 W 都等于 0 时程序结束。
输出描述:
1 输出小 A 走到迷宫出口最少需要花费多少秒,如果永远无法走到出口则输出“-1 ”。
BFS,注意struct的初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #include <bits/stdc++.h> using namespace std;const int maxn = 105 ;char m[maxn][maxn];int vis[maxn][maxn];int dir[4 ][2 ] = {0 , 1 , 1 , 0 , 0 , -1 , -1 , 0 };struct node { int x, y; int step; }; int bfs (int x, int y) memset (vis, 0 , sizeof (vis)); queue<node> q; node s = {x, y, 0 }; q.push (s); vis[x][y] = 1 ; int ans = -1 ; while (!q.empty ()){ node now = q.front (); q.pop (); if (m[now.x][now.y] == 'E' ){ ans = now.step; break ; } for (int i = 0 ; i < 4 ; i++){ int nx = now.x + dir[i][0 ]; int ny = now.y + dir[i][1 ]; if ((m[nx][ny]=='*' ||m[nx][ny]=='E' ) && vis[nx][ny]==0 ){ node tmp = {nx, ny, now.step+1 }; q.push (tmp); vis[nx][ny] = 1 ; } } } return ans; } int main () int h, w; while (cin >> h >> w){ if (h==0 && w==0 ) break ; memset (m, 0 , sizeof (m)); for (int i = 0 ; i < h; i++){ cin >> m[i]; } int sx, sy; for (int i = 0 ; i < h; i++){ for (int j = 0 ; j < w; j++){ if (m[i][j] == 'S' ){ sx = i; sy = j; } } } int ans = bfs (sx, sy); cout << ans << endl; } return 0 ; }
DFS也能解决,递归,时间很慢
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <bits/stdc++.h> using namespace std;const int maxn = 100 + 5 ;char m[maxn][maxn];int vis[maxn][maxn];int dir[4 ][2 ] = {1 , 0 , 0 , -1 , -1 , 0 , 0 , 1 };int ans;void dfs (int x, int y, int step) if (step >= ans) return ; if (m[x][y] == 'E' ){ ans = min (ans, step); return ; } for (int i = 0 ; i < 4 ; i++){ int nx = x + dir[i][0 ]; int ny = y + dir[i][1 ]; if ((m[nx][ny]=='*' ||m[nx][ny]=='E' )&&vis[nx][ny] == 0 ){ vis[nx][ny] = 1 ; dfs (nx, ny, step+1 ); vis[nx][ny] = 0 ; } } } int main () int w, h; while (cin >> w >> h){ if (w == 0 && h == 0 ) break ; int sx, sy; for (int i = 0 ; i < w; i++){ cin >> m[i]; for (int j = 0 ; j < h; j++){ if (m[i][j] == 'S' ){ sx = i; sy = j; } } } ans = 0x7ffffff ; dfs (sx, sy, 0 ); cout << ans << endl; } return 0 ; }
Hanoi塔问题
题目描述
(n阶Hanoi塔问题)假设有三个分别命名为A、B、C的塔座,在塔座A上插有n(n<20)个直径大小各不相同、依小到大编号为1,2,…,n的圆盘。现要求将A轴上的n个圆盘移至塔座C上并仍按同样顺序叠排,圆盘移动时必须遵循下列规则:
1)每次只能移动一个圆盘; 2)圆盘可以插在A、B、C中的任一塔座上;
3)任何时刻都不能将一个较大的圆盘压在较小的圆盘之上。
请通过编程来打印出移动的步骤.
输入输出格式
输入描述:
1 只有一组输入数据.输入数据N (),当输入0 时程序结束.
输出描述:
1 输出移动的步骤.如"A -->C","A -->B "等.每两的步骤之间有三个空格隔开,每输出5 个步骤就换行.详细的见Sample Output.
递归解决
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <bits/stdc++.h> using namespace std;int jud = 0 ;void hanoi (int n, char a, char b, char c) if (n == 1 ){ if ((jud+1 ) % 5 == 0 ) printf ("%c-->%c\n" , a, c); else printf ("%c-->%c " , a, c); jud++; return ; } hanoi (n-1 , a, c, b); hanoi (1 , a, b, c); hanoi (n-1 , b, a, c); } int main () int n; while (cin >> n){ if (n == 0 ) break ; jud = 0 ; hanoi (n, 'A' , 'B' , 'C' ); cout << endl; } return 0 ; }
石油储藏
题目描述
有一个GeoSurvComp地质勘探公司正在负责探测地底下的石油块。这个公司在一个时刻调查一个矩形区域,并且创建成一个个的格子用来表示众多正方形块。它然后使用测定设备单个的分析每块区域,决定是否有石油。一块有石油小区域被称为一个pocket,假设两个pocket是相邻的,然后他们就是相同石油块的一部分,石油块可能非常的大并且包涵很多的pocket。你的任务就是在一个网格中存在多少个石油块。输入首先给出图的大小,然后给出这个图。*代表没有石油,@代表存在石油 。输出每种情况下石油块的个数。
输入输出格式
输入描述:
1 输入包含一个或多个网格。 每个网格都以包含m和n 的行开始,网格中的行和列数为m和n ,以单个空格分隔。 如果m = 0 ,则表示输入结束。 否则为1 <= m <= 100 和1 <= n <=100 。这之后是m行,每行n 个字符(不计算行末字符)。 每个字符对应一个情节,要么是代表没有油的“ *”,要么是代表油囊的“ @”。
输出描述:
1 在水平,垂直或对角线上都算作相邻,输出每种情况下石油块的个数。
dfs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <bits/stdc++.h> using namespace std;const int maxn = 100 + 5 ;char m[maxn][maxn];int vis[maxn][maxn];int dir[8 ][2 ] = {1 , 0 , 0 , -1 , -1 , 0 , 0 , 1 , 1 , 1 , -1 , -1 , 1 , -1 , -1 , 1 };int ans;void dfs (int x, int y) vis[x][y] = 1 ; for (int i = 0 ; i < 8 ; i++){ int nx = x + dir[i][0 ]; int ny = y + dir[i][1 ]; if (m[nx][ny] == '@' && vis[nx][ny] == 0 ){ dfs (nx, ny); } } } int main () int w, h; while (cin >> w >> h){ if (w == 0 && h == 0 ) break ; memset (m, 0 , sizeof (m)); memset (vis, 0 , sizeof (vis)); for (int i = 0 ; i < w; i++){ cin >> m[i]; } ans = 0 ; for (int i = 0 ; i < w; i++){ for (int j = 0 ; j < h; j++){ if (m[i][j]=='@' &&vis[i][j] == 0 ){ ans ++; dfs (i, j); } } } cout << ans << endl; } return 0 ; }
图论
畅通工程2
题目描述
某省调查城镇交通状况,得到现有城镇道路统计表,表中列出了每条道路直接连通的城镇。省政府“畅通工程”的目标是使全省任何两个城镇间都可以实现交通(但不一定有直接的道路相连,只要互相间接通过道路可达即可)。问最少还需要建设多少条道路?
输入输出格式
输入描述:
1 2 3 4 5 6 7 8 测试输入包含若干测试用例。每个测试用例的第1行给出两个正整数,分别是城镇数目N ( < 1000 )和道路数目M;随后的M行对应M条道路,每行给出一对正整数,分别是该条道路直接连通的两个城镇的编号。为简单起见,城镇从1到N编号。 注意:两个城市之间可以有多条道路相通,也就是说 3 3 1 2 1 2 2 1 这种输入也是合法的 当N为0时,输入结束,该用例不被处理。
输出描述:
1 对每个测试用例,在1行里输出最少还需要建设的道路数目。
并查集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <bits/stdc++.h> using namespace std;const int maxn = 1000 +5 ;int f[maxn];void initial (int n) for (int i = 0 ; i < n; i++){ f[i] = i; } } int find (int x) if (x == f[x]) return x; else { f[x] = find (f[x]); return f[x]; } } int main () int n, m; while (cin >> n >> m){ if (n == 0 ) break ; initial (n); int x, y, ans = 0 ; for (int i = 0 ; i < m; i++){ cin >> x >> y; int fx = find (x); int fy = find (y); if (fx != fy){ ans++; f[fx] = fy; } } cout << n - ans - 1 << endl; } return 0 ; }
加入merge
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <bits/stdc++.h> using namespace std;const int maxn = 1000 +5 ;int f[maxn], rank[maxn];void initial (int n) for (int i = 0 ; i < n; i++){ f[i] = i; rank[i] = 1 ; } } int find (int x) if (x == f[x]) return x; else { f[x] = find (f[x]); return f[x]; } } void merge (int x, int y) int fx = find (x), fy = find (y); if (rank[x] <= rank[y]){ f[fx] = fy; } else { f[fy] = fx; } if (rank[fx] == rank[fy] && fx != fy){ rank[fy]++; } } int main () int n, m; while (cin >> n){ if (n == 0 ) break ; cin >> m; initial (n); int x, y, ans = 0 ; for (int i = 0 ; i < m; i++){ cin >> x >> y; int fx = find (x); int fy = find (y); if (fx != fy){ ans++; merge (fx, fy); } } cout << n - ans - 1 << endl; } return 0 ; }
畅通工程
题目描述
省政府“畅通工程”的目标是使全省任何两个村庄间都可以实现公路交通(但不一定有直接的公路相连,只要能间接通过公路可达即可)。经过调查评估,得到的统计表中列出了有可能建设公路的若干条道路的成本。现请你编写程序,计算出全省畅通需要的最低成本。
输入输出格式
输入描述:
1 测试输入包含若干测试用例。每个测试用例的第1 行给出评估的道路条数 N 、村庄数目M (N , M < =100 );随后的 N 行对应村庄间道路的成本,每行给出一对正整数,分别是两个村庄的编号,以及此两村庄间道路的成本(也是正整数)。为简单起见,村庄从1 到M编号。当N 为0 时,全部输入结束,相应的结果不要输出。
输出描述:
1 对每个测试用例,在1 行里输出全省畅通需要的最低成本。若统计数据不足以保证畅通,则输出“?” 。
克鲁斯卡尔算法+合并集(注释是因为不知道为什么加入rank会报错)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 #include <bits/stdc++.h> using namespace std;const int maxn = 100 +5 ;int f[maxn];struct node { int u, v, w; }; bool cmp (struct node a, struct node b) return a.w < b.w; } void initial (int n) for (int i = 0 ; i < n; i++){ f[i] = i; } } int find (int x) if (x == f[x]) return x; else { f[x] = find (f[x]); return f[x]; } } int main () int n, m; while (cin >> n >> m){ if (n == 0 ) break ; initial (m); struct node edge[n]; for (int i = 0 ; i < n; i++){ cin >> edge[i].u >> edge[i].v >> edge[i].w; } sort (edge, edge+n, cmp); int ans = 0 , r = 0 ; for (int i = 0 ; i < n; i++){ int fx = find (edge[i].u), fy = find (edge[i].v); if (fx != fy){ ans++; r += edge[i].w; f[fx] = fy; } } if (m - 1 > ans){ cout << "?" << endl; } else { cout << r << endl; } } return 0 ; }
最短路
题目描述
在每年的校赛里,所有进入决赛的同学都会获得一件很漂亮的t-shirt。但是每当我们的工作人员把上百件的衣服从商店运回到赛场的时候,却是非常累的!所以现在他们想要寻找最短的从商店到赛场的路线,你可以帮助他们吗?
输入输出格式
输入描述:
1 2 输入包括多组数据。每组数据第一行是两个整数N 、M (N <= 100 ,M <= 10000 ),N 表示成都的大街上有几个路口,标号为1 的路口是商店所在地,标号为N 的路口是赛场所在地,M 则表示在成都有几条路。N = M = 0 表示输入结束。接下来M 行,每行包括3 个整数A ,B ,C (1 <= A , B <= N , 1 <= C <= 1000 ), 表示在路口A 与路口B 之间有一条路,我们的工作人员需要C 分钟的时间走过这条路。 输入保证至少存在1 条商店到赛场的路线。
输出描述:
1 对于每组输入,输出一行,表示工作人员从商店走到赛场的最短时间
我写的spfa不能通过全部的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 #include <bits/stdc++.h> using namespace std;const int MAX = 0x7ffffff ;const int maxn = 105 ;struct edge { int u, v, w; edge (int u_, int v_, int w_){ u = u_; v = v_; w = w_; } }; vector<edge> edges; vector<int > gra[maxn]; int vis[maxn];int dis[maxn];void init () edges.clear (); for (int i = 0 ; i < maxn; i++){ dis[i] = maxn; vis[i] = 0 ; gra[i].clear (); } } void spfa (int s) dis[s] = 0 ; priority_queue<int > q; q.push (s); while (!q.empty ()){ int now = q.top (); q.pop (); vis[now] = 0 ; for (int i = 0 ; i < gra[now].size (); i++){ edge e = edges[gra[now][i]]; if (dis[e.v] > dis[now] + e.w){ dis[e.v] = dis[now] + e.w; if (!vis[e.v]){ vis[e.v] = 1 ; q.push (e.v); } } } } } void addedge (int a, int b, int c) edges.push_back (edge (a, b, c)); int sz = edges.size () - 1 ; gra[a].push_back (sz); } int main () int n, m; while (cin >> n >> m){ if (m == 0 && n == 0 ) break ; init (); int a, b, c; for (int i = 0 ; i < m; i++){ cin >> a >> b >> c; addedge (a, b, c); addedge (b, a, c); } spfa (1 ); cout << dis[n] << endl; } return 0 ; }
floyd全源最短路径也过不了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <bits/stdc++.h> using namespace std;const int MAX = 0x3f3f ;const int maxn = 105 ;int gra[maxn][maxn];int main () int n, m; while (cin >> n >> m){ if (m == 0 && n == 0 ) break ; for (int i = 0 ; i <= n; i++){ for (int j = 0 ; j <= n; j++){ if (i == j) gra[i][j] = 0 ; else gra[i][j] = MAX; } } int a, b, c; for (int i = 0 ; i < m; i++){ cin >> a >> b >> c; if (c < gra[a][b]){ gra[a][b] = c; gra[b][a] = c; } } for (int k = 1 ; k <= n; k++){ for (int i = 1 ; i <= n; i++){ for (int j = 1 ; j <= n; j++){ if (gra[k][i] == MAX && gra[i][j] == MAX) continue ; if (gra[k][j] == MAX || gra[k][j] > gra[k][i] + gra[i][j]){ gra[k][j] = gra[k][i] + gra[i][j]; } } } } cout << gra[1 ][n] << endl; } return 0 ; }
确定比赛名次
题目描述
有N个比赛队(1<=N<=500),编号依次为1,2,3,。。。。,N进行比赛,比赛结束后,裁判委员会要将所有参赛队伍从前往后依次排名,但现在裁判委员会不能直接获得每个队的比赛成绩,只知道每场比赛的结果,即P1赢P2,用P1,P2表示,排名时P1在P2之前。现在请你编程序确定排名。
输入输出格式
输入描述:
1 输入有若干组,每组中的第一行为二个数N(1 <=N <=500 ),M;其中N表示队伍的个数,M表示接着有M行的输入数据。接下来的M行数据中,每行也有两个整数P1 ,P2 表示即P1 队赢了P2 队。
输出描述:
1 2 3 给出一个符合要求的排名。输出时队伍号之间有空格,最后一名后面没有空格。 其他说明:符合条件的排名可能不是唯一的,此时要求输出时编号小的队伍在前;输入数据保证是正确的,即输入数据确保一定能有一个符合要求的排名。
拓扑排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <bits/stdc++.h> using namespace std;const int maxn = 505 ;int d[maxn];int mpt[maxn][maxn];vector<int > toposort (int n) { vector<int > ans; priority_queue<int , vector<int >, greater<int > > q; for (int i = 1 ; i <= n; i++) { if (d[i] == 0 ) q.push (i); } while (!q.empty ()){ int now = q.top (); ans.push_back (now); q.pop (); for (int i = 1 ; i <= n; i++){ if (mpt[now][i] == 1 ){ if (--d[i] == 0 ){ q.push (i); } } } } return ans; } int main () int n, m; while (cin >> n >> m){ int a, b; memset (d, 0 , sizeof (d)); memset (mpt, 0 , sizeof (mpt)); for (int i = 0 ; i < m; i++){ cin >> a >> b; if (mpt[a][b] == 0 ){ mpt[a][b] = 1 ; d[b]++; } } vector<int > ans = toposort (n); for (int i = 0 ; i < ans.size (); i++){ cout << ans[i] << " " ; } cout << endl; } return 0 ; }
动态规划
分而治之
最后一章了!
递推
比较重要的就是斐波那契数列了,f[n] = f[n-1] + f[n-2]
最大字段和
最大序列和
题目描述
给出一个整数序列S,其中有N个数,定义其中一个非空连续子序列T中所有数的和为T的“序列和”。
对于S的所有非空连续子序列T,求最大的序列和。
变量条件:N为正整数,N≤1000000,结果序列和在范围(-263,2 63-1)以内。
输入输出格式
输入描述:
1 第一行为一个正整数N ,第二行为N 个整数,表示序列中的数。
输出描述:
1 2 输入可能包括多组数据,对于每一组输入数据, 仅输出一个数,表示最大序列和。
范围比较大,要初始化longlong
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <bits/stdc++.h> using namespace std;long long a[1000005 ], d[1000005 ];long long maxx;int main () int n; while (cin >> n){ for (int i = 0 ; i < n; i++){ cin >> a[i]; } d[0 ] = a[0 ]; maxx = a[0 ]; for (int i = 1 ; i < n; i++){ d[i] = max (d[i-1 ]+a[i], a[i]); maxx = max (maxx, d[i]); } cout << maxx << endl; } return 0 ; }
字符串区间翻转
题目描述
小诺有一个由0和1组成的字符串
现在小诺有一次机会,可以选择一个任意的区间[L,R],将该区间内的所有字符串进行翻转(即0->1,1->0)。
请问小诺经过一次翻转之后字符串中最多会有多少个1?
输入输出格式
输入描述:
1 2 第一行输入一个正整数n ,表示字符串长度,n <=10 ^7 。 接下来一行一个输入一个01 字符串。
输出描述:
最大连续子串可以映射到最大序列和问题,这题要找最多0的个数,把0变成1,1变成-1,那就是标准的最大连续序列和了;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <bits/stdc++.h> using namespace std;int a[10000005 ];int d[10000005 ];int main () int n; string s; while (cin >> n){ cin >> s; int len = s.size (); for (int i = 0 ; i < len; i++){ if (s[i] == '1' ){ a[i] = -1 ; } else { a[i] = 1 ; } } d[0 ] = a[0 ]; int ans = 0 ; for (int i = 0 ; i < n; i++){ d[i] = max (d[i-1 ]+a[i], a[i]); ans = max (d[i], ans); } for (int i = 0 ; i < n; i++){ if (s[i] == '1' ){ ans++; } } cout << ans << endl; } return 0 ; }
最大连续子序列
题目描述
给定K个整数的序列{ N1, N2, ..., NK },其任意连续子序列可表示为{ Ni,
Ni+1, ..., Nj },其中 1 <= i <= j <=
K。最大连续子序列是所有连续子序列中元素和最大的一个,例如给定序列{ -2,
11, -4, 13, -5, -2 },其最大连续子序列为{ 11, -4, 13
},最大和为20。现在增加一个要求,即还需要输出该子序列的第一个和最后一个元素。
输入输出格式
输入描述:
1 测试输入包含若干测试用例,每个测试用例占2 行,第1 行给出正整数K ( K < 10000 ) ,第2 行给出K 个整数,中间用空格分隔。当K 为0 时,输入结束,该用例不被处理。
输出描述:
1 对每个测试用例,在1 行里输出最大和、最大连续子序列的第一个和最后一个元素,中间用空格分隔。如果最大连续子序列不唯一,则输出序号i 和j最小的那个(如输入样例的第2 、3 组)。若所有K个元素都是负数,则定义其最大和为0 ,输出整个序列的首尾元素。
主要是左右边界的判断,有人是只找最大子序列和的右边界,然后一直往前减减到0为止得到左边界,比较容易想到
如果要在得到最大子序列的时候得到左边界,需要满足的条件是d[i-1]小于0并且这一轮的d[i]要比现有子序列大(直接把前面算的子序列和舍弃掉);右边界比较好找。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <bits/stdc++.h> using namespace std;const int maxn = 10000 +5 ;int a[maxn];int d[maxn];int main () int n; while (cin >> n){ if (n == 0 ) break ; memset (a, 0 , sizeof (a)); memset (d, 0 , sizeof (d)); for (int i = 0 ; i < n; i++){ cin >> a[i]; } d[0 ] = a[0 ]; int ans = a[0 ], l = a[0 ], r = a[0 ], l_ = a[0 ]; for (int i = 1 ; i < n; i++){ if (d[i-1 ]+a[i] < a[i]){ d[i] = a[i]; l_ = a[i]; } else { d[i] = d[i-1 ] + a[i]; } if (ans < d[i]){ ans = d[i]; r = a[i]; l = l_; } } if (ans < 0 ){ ans = 0 ; l = a[0 ]; r = a[n-1 ]; } printf ("%d %d %d\n" , ans, l, r); } return 0 ; }
最大子串和
题目描述
输入n个整数的序列,求它的最大子串和,并输出对应的数。
输入输出格式
输入描述:
1 2 3 多组测试数据。 第一行输入一个整数n (0 <n <=100 )。 接下来一行输入n 个数用空格隔开,保证每个数的绝对值小于1000 。
输出描述:
1 2 第一行输出所求子串的序列,如果有多个答案,输出靠前的答案。 第二行输出最大子串和。
我是真服了,上一题的又过不了。
但这一题规模比较小,可以爆破。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <bits/stdc++.h> using namespace std;int main () int n; while (cin >> n){ int a[n+5 ] = {0 }, d[n+5 ] = {0 }; int max = -1e7 , l=0 , r=0 ; for (int i = 1 ; i <= n; i++){ cin >> a[i]; d[i] = d[i-1 ] + a[i]; } for (int i = 1 ; i <= n; i++){ for (int j = 0 ; i+j <= n; j++){ if (d[i+j] - d[i-1 ] > max){ max = d[i+j] - d[i-1 ]; l = i; r = i+j; } } } for (int i = l; i <= r; i++){ cout << a[i] << " " ; } cout << endl; printf ("%d\n" , max); } return 0 ; }
最长升序子序列
一种n^2的做法,状态转移方程为
还有一种基于二分和贪心的算法,为O(nlogn)
最大上升子序列和
题目描述
一个数的序列bi,当b1 < b2 < ... <
bS的时候,我们称这个序列是上升的。对于给定的一个序列(a1, a2,
...,aN),我们可以得到一些上升的子序列(ai1, ai2, ..., aiK),这里1 <=
i1 < i2 < ... < iK <= N。比如,对于序列(1, 7, 3, 5, 9, 4,
8),有它的一些上升子序列,如(1, 7), (3, 4,
8)等等。这些子序列中序列和最大为18,为子序列(1, 3, 5, 9)的和.
你的任务,就是对于给定的序列,求出最大上升子序列和。注意,最长的上升子序列的和不一定是最大的,比如序列(100,
1, 2, 3)的最大上升子序列和为100,而最长上升子序列为(1, 2, 3)。
输入输出格式
输入描述:
1 2 输入包含多组测试数据。 每组测试数据由两行组成。第一行是序列的长度N (1 <= N <= 1000 )。第二行给出序列中的N 个整数,这些整数的取值范围都在0 到10000 (可能重复)。
输出描述:
注意这题是最大上升子序列和,而不是最长上升子序列,直接dp遍历了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <bits/stdc++.h> using namespace std;const int maxn = 1005 ;int a[maxn];int d[maxn];int LIS (int n) int ans = 0 ; for (int i = 1 ; i <= n; i++){ d[i] = a[i]; for (int j = 0 ; j < i; j++){ if (a[j] < a[i]){ d[i] = max (d[i], d[j] + a[i]); } } ans = max (d[i], ans); } return ans; } int main () int n; while (cin >> n){ for (int i = 1 ; i <= n; i++){ cin >> a[i]; } cout << LIS (n) <<endl; } return 0 ; }
拦截导弹
题目描述
某国为了防御敌国的导弹袭击,开发出一种导弹拦截系统。但是这种导弹拦截系统有一个缺陷:虽然它的第一发炮弹能够到达任意的高度,但是以后每一发炮弹都不能高于前一发的高度。某天,雷达捕捉到敌国的导弹来袭,并观测到导弹依次飞来的高度,请计算这套系统最多能拦截多少导弹。拦截来袭导弹时,必须按来袭导弹袭击的时间顺序,不允许先拦截后面的导弹,再拦截前面的导弹。
输入输出格式
输入描述:
1 2 3 每组输入有两行, 第一行,输入雷达捕捉到的敌国导弹的数量k(k<= 25 ), 第二行,输入k个正整数,表示k枚导弹的高度,按来袭导弹的袭击时间顺序给出,以空格分隔。
输出描述:
1 每组输出只有一行,包含一个整数,表示最多能拦截多少枚导弹。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <bits/stdc++.h> using namespace std;const int maxn = 30 ;int a[maxn];int d[maxn];int LIS (int n) int ans = 0 ; for (int i = 1 ; i <= n; i++){ d[i] = 1 ; for (int j = 0 ; j <i; j++){ if (a[j] >= a[i]){ d[i] = max (d[i], d[j] + 1 ); } } ans = max (d[i], ans); } return ans; } int main () int n; while (cin >> n){ memset (d, 0 , sizeof (d)); memset (a, 0 , sizeof (a)); for (int i = 1 ; i <= n; i++){ cin >> a[i]; } cout << LIS (n) <<endl; } return 0 ; }
合唱队形
题目描述
N位同学站成一排,音乐老师要请其中的(N-K)位同学出列,使得剩下的K位同学不交换位置就能排成合唱队形。
合唱队形是指这样的一种队形:设K位同学从左到右依次编号为1, 2, …,
K,他们的身高分别为T1, T2, …, TK, 则他们的身高满足T1 < T2 < …
< Ti , Ti > Ti+1 > … > TK (1 <= i <= K)。
你的任务是,已知所有N位同学的身高,计算最少需要几位同学出列,可以使得剩下的同学排成合唱队形。
输入输出格式
输入描述:
1 2 输入的第一行是一个整数N(2 <= N <= 100 ),表示同学的总数。 第一行有n个整数,用空格分隔,第i个整数Ti(130 <= Ti <= 230 )是第i位同学的身高(厘米)。
输出描述:
1 2 可能包括多组测试数据,对于每组数据, 输出包括一行,这一行只包含一个整数,就是最少需要几位同学出列。
正着排一遍,再倒着排一遍,找最大的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <bits/stdc++.h> using namespace std;const int maxn = 105 ;int a[maxn];int d1[maxn];int d2[maxn];int main () int n; while (cin >> n){ memset (d1, 0 , sizeof (d1)); memset (d2, 0 , sizeof (d2)); memset (a, 0 , sizeof (a)); for (int i = 1 ; i <= n; i++){ cin >> a[i]; } for (int i = 1 ; i <= n; i++){ d1[i] = 1 ; for (int j = 1 ; j < i; j++){ if (a[j] < a[i]){ d1[i] = max (d1[i], d1[j]+1 ); } } } for (int i = n; i >= 1 ; i--){ d2[i] = 1 ; for (int j = n; j > i; j--){ if (a[j] < a[i]){ d2[i] = max (d2[i], d2[j]+1 ); } } } int ans = 0 ; for (int i = 1 ; i <= n; i++){ int tmp = d1[i] + d2[i]; ans = max (ans, tmp); } cout << n-ans+1 << endl; } return 0 ; }
最长递减子序列
题目描述
输入数字n,和n个整数,输出该数字串中的最长递减序列
输入输出格式
输入描述:
输出描述:
先得到最长递减子序列长度,并算每一个元素的上一个的序号;然后找到d[i =
ans的元素位置;再根据pre往前得到最长递减子序列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <bits/stdc++.h> using namespace std;const int maxn = 1005 ;int a[maxn];int d[maxn];int pre[maxn]; int main () int n; while (cin >> n){ memset (d, 0 , sizeof (d)); memset (a, 0 , sizeof (a)); memset (pre, 0 , sizeof (pre)); int b[n] = {0 }; for (int i = 0 ; i < n; i++){ cin >>a[i]; } int ans = 0 ; for (int i = 0 ; i < n; i++){ d[i] = 1 ; for (int j = 0 ; j < i; j++){ if (a[j] > a[i]){ int tmp = d[j]+1 ; if (tmp > d[i]){ d[i] = tmp; pre[i] = j; } } } ans = max (ans, d[i]); } int t = n-1 , l; while (t){ if (d[t] == ans){ l = t; } t--; } t = ans-1 ; for (; l!=0 ; l = pre[l]){ b[t--] = a[l]; } b[t] = a[l]; for (int i = 0 ; i < ans; i++){ cout << b[i] << " " ; } cout << endl; } return 0 ; }
最长公共子序列
状态转移方程:
Coincidence
题目描述
Find a longest common subsequence of two strings.
输入输出格式
输入描述:
1 First and second line of each input case contain two strings of lowercase character a …z. There are no spaces before , inside or after the strings. Lengths of strings do not exceed 100.
输出描述:
1 For each case , output k – the length of a longest common subsequence in one line .
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <bits/stdc++.h> using namespace std;const int maxn = 105 ;int d[maxn][maxn];int main () string a, b; while (cin >> a >> b){ memset (d, 0 , sizeof (d)); int la = a.size (); int lb = b.size (); for (int i = 1 ; i<=la; i++){ for (int j = 1 ; j <= lb; j++){ if (a[i-1 ] == b[j-1 ]){ d[i][j] = d[i-1 ][j-1 ]+1 ; } else { d[i][j] = max (d[i-1 ][j], d[i][j-1 ]); } } } cout << d[la][lb] << endl; } return 0 ; }
最长连续公共子序列
题目描述
Time Limit: 1000 ms Memory Limit: 256 mb
输入两个字符串s1,s2。输出最长连续公共子串长度和最长连续公共子串。
输入输出格式
输入描述:
1 2 多组数据输入。 输入两个字符串s1 ,s2 ,长度不大于100 ,以空格隔开。
输出描述:
这种情况的状态转移方程为:
然后每次得到最长公共子串获取其末尾的下标,再通过长度就可打印序列(注意要最后一个,所以有等号)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <bits/stdc++.h> using namespace std;const int maxn = 105 ;int d[maxn][maxn];int main () string a, b; while (cin >> a >> b){ memset (d, 0 , sizeof (d)); int la = a.size (); int lb = b.size (); int res = 0 , l, r; for (int i = 1 ; i<=la; i++){ for (int j = 1 ; j <= lb; j++){ if (a[i-1 ] == b[j-1 ]){ d[i][j] = d[i-1 ][j-1 ]+1 ; if (d[i][j] >= res){ res = d[i][j]; l = i; r = j; } } else { d[i][j] = 0 ; } } } cout << res << endl; for (int i = l - res; i < l; i++){ cout <<a[i]; } cout <<endl; } return 0 ; }
骑车路线
题目描述
Tomislav最近发现自己的身材完全走样了,她走楼梯都变得很累。一天早上她起来以后,她决定恢复姣好的身材。她最喜欢的运动是骑自行车,因此她决定在本地的小山上做一次旅行。
她骑自行车的路线可以描述为N个数字的数列,每个数字表示每一段路地海拔高度。Tomislav最感兴趣的是最长的高度一直上升的子序列,她称这一段路为爬坡,Tomislav只想考虑这段爬坡的高度差(即开始和最后的数字的差距),而不是什么路程长度。
一段爬坡路被定义为至少两个连续的上升数列。例如,我们考虑如下路线数列12
3 5 7 10 6 1 11,这里有两个爬坡,第一个爬坡(3 5 7
10)的高度差是7,第二个爬坡的高度差是10(1 11)。
帮助Tomislav计算高度差最大的爬坡的高度差。
输入输出格式
输入描述:
1 2 3 多组测试数据输入。 第一行是一个正整数N (1 <= N <= 1000 ), 描述了路线数列。 第二行有N 个正整数,每个正整数Pi (1 <= Pi <= 1000 )表示相应路段的海拔高度。
输出描述:
1 所有爬坡中的最大高度差,如果路线数列里面没有爬坡,就输出0。
我想的是用d[i]来定义到i为止最大的高度差,但过不了所有用例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <bits/stdc++.h> using namespace std;const int maxn = 1005 ;int a[maxn];int d[maxn];int main () int n; while (cin >> n){ for (int i = 0 ; i<n; i++){ cin >> a[i]; } int res = 0 ; for (int i = 0 ; i <n; i++){ d[i] = 0 ; for (int j = 0 ; j < i; j++){ if (d[i] < d[j] || d[i] < (a[i] - a[j])) d[i] = max (d[j], a[i] - a[j]); } res = max (res, d[i]); } cout << res << endl; } return 0 ; }
misc
骨牌 - 加强版
题目描述
有2n 的地板,用1 2和 2*1
的骨牌进行铺地板。问共有多少种情况。
结果对 999983 取余,1<=n<=1e12。
输入输出格式
输入描述:
输出描述:
其实就是斐波那契数列的矩阵快速幂
\[
[f(n-1), f(n-2)]*\begin{bmatrix}1 & 1\\1&0 \end{bmatrix} =
[f(n), f(n-1)]\\
所以\begin{bmatrix}f(1) & f(2)\\0&0 \end{bmatrix} *
(\begin{bmatrix}1 & 0\\1&1 \end{bmatrix})^n =
\begin{bmatrix}f(n+2) & f(n+1)\\0&0 \end{bmatrix}
\]
无优化的递归是2^n,记忆化处理是n,但由于数据量是1e12,递归过深会爆栈
改成递推是O(n),也处理不了,变成矩阵乘法是O(8n)
再加上快速幂就是O(8logn)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <bits/stdc++.h> using namespace std;typedef long long ll;const ll mod = 999983 ;struct matrix { ll m[2 ][2 ]; }; matrix multi (struct matrix a, struct matrix b) { struct matrix tmp; for (int i = 0 ; i < 2 ; i++){ for (int j = 0 ; j < 2 ; j++){ tmp.m[i][j] = 0 ; for (int k = 0 ; k < 2 ; k++){ tmp.m[i][j] = (tmp.m[i][j] + a.m[i][k] * b.m[k][j]) % mod; } } } return tmp; } int fastpower (ll n) struct matrix base, ans; base.m[0 ][0 ] = base.m[0 ][1 ] = base.m[1 ][0 ] = 1 ; base.m[1 ][1 ] = 0 ; ans.m[0 ][0 ] = ans.m[1 ][1 ] = 1 ; ans.m[0 ][1 ] = ans.m[1 ][0 ] = 0 ; while (n){ if (n & 1 ){ ans = multi (ans, base); } base = multi (base, base); n >>= 1 ; } return ans.m[0 ][0 ]; } int main () ll n; while (cin >> n){ if (n == 1 ) cout << 1 << endl; else if (n == 2 ) cout << 2 << endl; else { cout << fastpower (n) << endl; } } return 0 ; }